| CPC G06F 40/295 (2020.01) [G06F 16/3347 (2019.01); G06F 40/253 (2020.01); G06N 5/04 (2013.01); G06N 20/00 (2019.01); G06F 40/30 (2020.01); G06F 2216/03 (2013.01)] | 16 Claims |
|
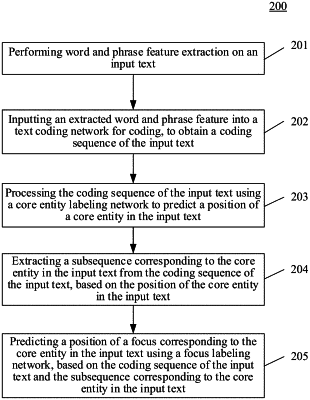
1. A method for mining an entity focus in a text, the method comprising:
performing word and phrase feature extraction on an input text, wherein the input text comprises a plurality of entities comprising a core entity representing a subject of the input text;
inputting an extracted word and phrase feature into a text coding network for coding, to obtain a coding sequence of the input text;
predicting a position of the core entity in the input text by processing the coding sequence of the input text using a core entity labeling network, the position of the core entity being a position where the core entity is located in the input text, wherein predicting the position of the core entity in the input text by processing the coding sequence of the input text using a core entity labeling network, comprises:
inputting the coding sequence of the input text into the core entity labeling network to predict a probability of each word string in the input text being the core entity, and labeling a starting position and an ending position of the core entity respectively using a double pointer based on the probability of each word string in the input text being the core entity, wherein the starting position is a position where a first word of the core entity is located in the input text, and the ending position is a position where a last word of the core entity is located in the input text;
extracting a subsequence corresponding to the core entity in the input text from the coding sequence of the input text, based on the position of the core entity in the input text; and
predicting a position of a focus corresponding to the core entity in the input text using a focus labeling network, based on the coding sequence of the input text and the subsequence corresponding to the core entity in the input text, wherein the focus corresponding to the core entity is a part of the input text describing the core entity, and the position of the focus is a position where the focus is located in the input text.
|