| CPC G06F 16/951 (2019.01) [G06F 7/08 (2013.01); G06F 16/353 (2019.01)] | 16 Claims |
|
1. A method for defining and utilizing a content relevance model for a particular category to at least in part determine whether a content segment is relevant to the particular category, the method comprising:
executing code by a processor for a first computer system to cause the processor of the first computer system to perform operations comprising:
sending a first set of content segments that contain content relevant to the particular category and a second set of content segments that contain content not relevant to the particular category; and
receiving, from a second computer system, documents that are relevant to one or more particular categories, wherein the documents are identified by a second computer system executing code by a processor to perform operations comprising:
receiving the first set of content segments;
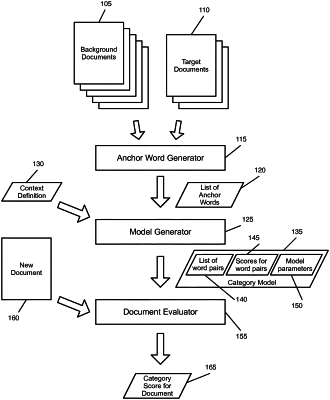
identifying a set of key word sets more likely to appear in the first set of content segments than the second set of content segments; and
defining a content relevance model that comprises a set of groups of word sets and a score for each group, each of the groups of word sets comprising a key word set from the set of key word sets and at least one word set found in a context of the key word set in at least one of the received content segments, wherein defining the content relevance model further comprises:
determining the set of key word sets for the particular category based on an analysis of (i) a first set of content segments defined as relevant to the particular category and (ii) a second set of content segments defined as not relevant to the particular category;
determining (i) a set of pairs of word sets that each comprise a key word set and a word set that appears in a defined context of the keyword and (ii) a score for each of the word set pairs, the score for a particular word set pair quantifying a likelihood that a content segment containing the word set pair is relevant to the particular category; and
defining a content relevance model for the particular category, the content relevance model comprising (i) a context definition and (ii) the set of word set pairs and corresponding scores;
utilizing the content relevance model in a system to identify content segments in documents for relevancy to the one or more particular categories;
providing the documents that are relevant to the one or more particular categories to the first computer system.
|