| CPC G06F 16/367 (2019.01) [G06F 18/253 (2023.01); G06F 40/279 (2020.01); G06V 10/426 (2022.01); G06V 10/454 (2022.01); G06V 10/764 (2022.01); G06V 10/811 (2022.01); G06V 10/82 (2022.01); G06N 3/02 (2013.01)] | 16 Claims |
|
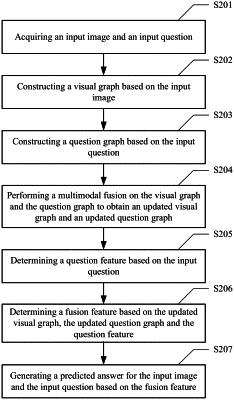
1. A method for visual question answering, comprising:
acquiring an input image and an input question;
constructing a visual graph based on the input image, wherein the visual graph comprises a first node feature and a first edge feature;
constructing a question graph based on the input question, wherein the question graph comprises a second node feature and a second edge feature;
performing a multimodal fusion on the visual graph and the question graph to obtain an updated visual graph and an updated question graph;
determining a question feature based on the input question;
determining a fusion feature based on the updated visual graph, the updated question graph and the question feature; and
generating a predicted answer for the input image and the input question based on the fusion feature;
wherein the performing the multimodal fusion on the visual graph and the question graph comprises: performing at least one round of multimodal fusion operation, wherein each of the at least one round of multimodal fusion operation comprises:
encoding the first node feature by using a first predetermined network based on the first node feature and the first edge feature, to obtain an encoded visual graph;
encoding the second node feature by using a second predetermined network based on the second node feature and the second edge feature, to obtain an encoded question graph; and
performing a multimodal fusion on the encoded visual graph and the encoded question graph by using a graph match algorithm, to obtain the updated visual graph and the updated question graph;
wherein the first predetermined network comprises: a first fully connected layer, a first graph convolutional layer and a second graph convolutional layer, and the encoding the first node feature comprises:
mapping the first node feature to a first feature by using the first fully connected layer, wherein a number of spatial dimensions of the first feature equals to a predetermined number;
processing the first feature by using the first graph convolutional layer to obtain a second feature;
processing the second feature by using the second graph convolutional layer to obtain the encoded first node feature; and
constructing the encoded visual graph by using the encoded first node feature and the first edge feature.
|