| CPC G10L 13/10 (2013.01) [G10L 25/30 (2013.01)] | 10 Claims |
|
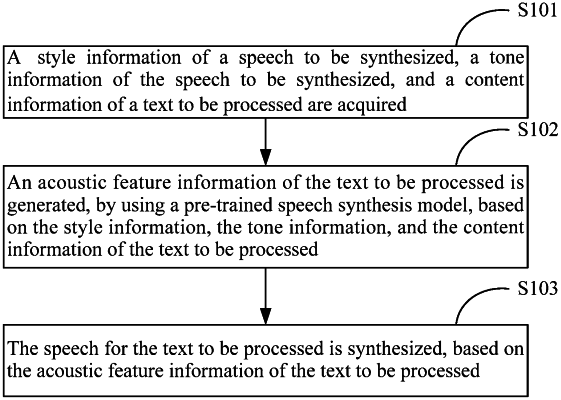
1. A method of synthesizing a speech, comprising:
acquiring a style information of a speech to be synthesized, a tone information of the speech to be synthesized, and a content information of a text to be processed;
generating an acoustic feature information of the text to be processed, by using a pre-trained speech synthesis model, based on the style information, the tone information, and the content information of the text to be processed; and
synthesizing the speech for the text to be processed, based on the acoustic feature information of the text to be processed,
wherein the acquiring the style information of the speech to be synthesized comprises:
acquiring a description information of an input style of a user; and determining a style identifier, from a preset style table, corresponding to the input style according to the description information of the input style, as the style information of the speech to be synthesized.
|