| CPC G06N 3/049 (2013.01) [G06F 9/44505 (2013.01); G06F 9/544 (2013.01); G06N 3/082 (2013.01)] | 19 Claims |
|
1. A semiconductor package comprising:
a plurality of dice each comprising:
a central controller;
a global memory buffer; and
a plurality of processing elements each comprising:
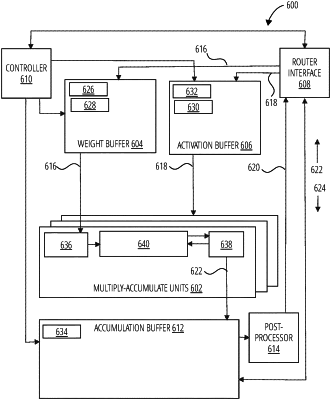
a weight buffer to receive from the central controller weight values for a neural network;
an activation buffer to receive activation values for the neural network;
an accumulation memory buffer to collect partial sum values;
a plurality of multiply-accumulate units to combine, in parallel, the weight values and the activation values into the partial sum values, each of the multiply-accumulate units comprising:
a weight collection buffer disposed in a data flow between the multiply-accumulate unit and the weight buffer; and
a partial sum collection buffer disposed in the data flow between the multiply-accumulate unit and the accumulation memory buffer.
|