| CPC G06F 16/285 (2019.01) [G06F 1/28 (2013.01); G06F 17/16 (2013.01); G06Q 30/0205 (2013.01); G06Q 50/06 (2013.01)] | 20 Claims |
|
1. A method of a power user classification based on distributed K-means, comprising:
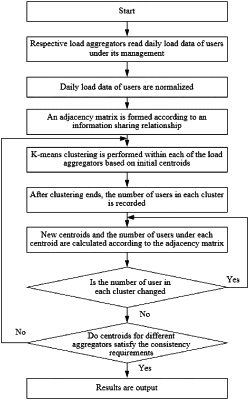
S1, obtaining, by N load aggregators, power consumption data of power users managed by the respective load aggregators, the power consumption data comprising serial numbers of the power users and time series load data of the power users;
S2, performing, by each of the load aggregators, a normalization operation on the time series load data of the power users managed by the load aggregator according to a uniform normalization criterion;
S3, forming a N×N dimensional adjacency matrix A according to an information sharing relationship of the load aggregators;
S4, performing, by each load aggregator, K-means clustering on the time series load data of the power users managed by the load aggregator after the normalization operation in the step S2, to obtain respective centroids and user groups characterized by the respective centroids; sharing, by the respective load aggregators, the centroids and the number of users under the respective centroids based on the adjacency matrix in the step S3; performing overall iterations repeatedly according to a corresponding function; and obtaining consistent centroids by multiple load aggregators; and
S5, after the overall iteration ends, obtaining, by the respective load aggregators, the consistent centroids consistent with K-means centroids based on global data, to realize user classification.
|