| CPC G10L 13/086 (2013.01) [G06F 16/345 (2019.01); G06F 40/279 (2020.01); G10L 13/10 (2013.01)] | 19 Claims |
|
1. A computer-implemented method, comprising:
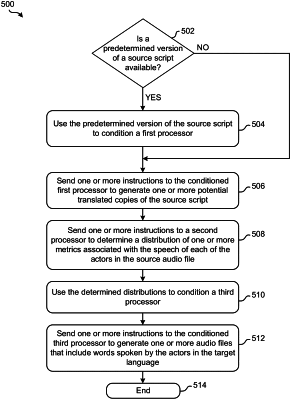
determining whether a predetermined version of a source script is available, wherein words in the source script are in a source language and words in the predetermined version of the source script are in a target language, wherein the predetermined version of the source script identifies specific ones of the words in the predetermined version that are to be retained in a generated script, wherein the words in the source script directly correspond to words spoken by actors in a source audio file, the source audio file corresponding to a video file;
in response to determining that the predetermined version of the source script is available, using the predetermined version of the source script to condition a first processor;
sending one or more instructions to the conditioned first processor to generate a translated copy of a first version of the source script by translating words in the first version of the source script from the source language to the target language;
sending one or more instructions to a second processor to determine a distribution of one or more metrics associated with speech of the actors in the source audio file;
using the distributions to condition a third processor;
sending one or more instructions to the conditioned third processor to generate a plurality of different potential audio files and a number of potential translated copies of the first version of the source script, the potential audio files including words spoken in the target language,
wherein the words spoken in the potential audio files directly correspond to words in the generated translated copy of the first version of the source script;
evaluating each respective pair of the potential audio files and the potential translated copies of the first version of the source script;
identifying one of the respective pairs as a closest match to lip movement of the actors in the video file that corresponds with the source audio file; and
sending one or more instructions to merge the potential audio file of the identified respective pair with the video file.
|