| CPC G06Q 30/04 (2013.01) [G06F 16/24568 (2019.01); G06F 16/2462 (2019.01)] | 20 Claims |
|
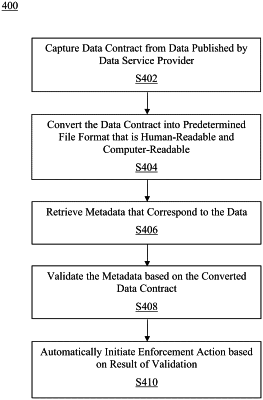
1. A method for facilitating automated enforcement of a data publication and usage contract, the method being implemented by at least one processor, the method comprising:
capturing, by the at least one processor and from a data stream between a data service provider and a data consumer, at least one data contract from data that is published by the data service provider, the at least one data contract including at least one data contract element, and the at least one data contract is between the data service provided and the data consumer for utilizing target data of the data service provider, wherein the at least one data contract captured includes data transitivity information indicating whether the data consumer changes into a data publisher in a downstream process;
performing recursive data refinement via an assembly of tools within a data lake environment, wherein the recursive data refinement progressively processes raw data that is initially unreadable by a machine, republishes the processed raw data, and document the republished data for readability by the machine, and wherein the recursive data refinement includes:
receiving, via a data ingestion component, the raw data that is published from a networked repository;
generating a conformed data set from the raw data based on a conformation parameter;
retrieving, via a communication interface, a feature configuration;
generating, in real-time, a feature data set from the conformed data set based on the feature configuration; and
publishing the feature data set, wherein the feature data set is published to the data ingestion component;
converting, by the at least one processor, the captured at least one data contract into a predetermined file format to enable leveraging of a code versioning tool for performing code versioning, wherein the predetermined file format is a machine readable format processable by a machine learning model;
retrieving, by the at least one processor, metadata that correspond to the data, the metadata including usage information that relates to a consumption of the data by the data consumer;
validating, by the at least one processor, the retrieved metadata based on the converted at least one data contract, wherein the validating includes comparing the at least one data contract element in the converted at least one data contract to a corresponding element in the metadata;
transforming and encoding the validated metadata into at least one feature;
predicting, using the machine learning model provided on an enterprise analytics platform and based on the at least one feature and a status of the data consumer as the data consumer or data publisher, a possibility of violation of the at least one data contract and storing the possibility of violation in a database as a prediction;
updating, by the machine learning model, the stored prediction based on subsequent data published by the data service provider; and
automatically initiating, by the at least one processor and based on an updated prediction, at least one enforcement action based on a result of the validating, wherein the at least one enforcement action includes restriction to the target data of the data service provider prior to a violation of the at least one data contract based on the updated prediction by the machine learning model.
|