| CPC G06F 9/3871 (2013.01) [G06F 9/3877 (2013.01); G06F 9/4881 (2013.01); G06N 3/063 (2013.01)] | 9 Claims |
|
1. A processor implemented method to process asynchronous and distributed training tasks, the method further comprising:
creating via one or more hardware processors, a work queue (Q) with a set of predefined number of tasks, where each task comprises of a training data obtained from one or more sources, and allocating estimated resources to process the work queue (Q) asynchronously;
fetching via the one or more hardware processors, at least at least one of a set of central processing units (CPUs) information and a set of graphics processing units (GPUs) information of the current environment where the task is being processed;
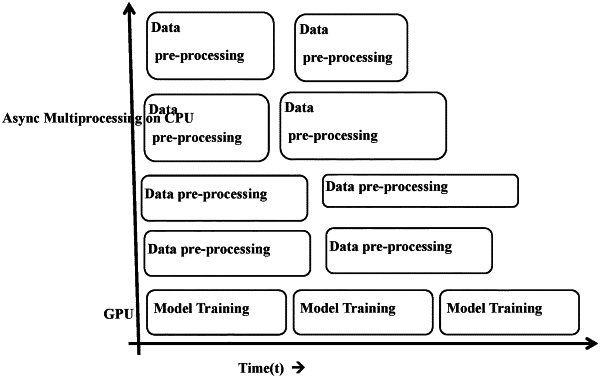
computing via the one or more hardware processors 104, by using a resource allocator, a number of parallel processes (p) queued on each CPU, a number of parallel processes (q) queued on each GPU, a number of iterations, and a flag status; and
initiating via the one or more hardware processors, a parallel process asynchronously on the work queue (Q) to train a set of deep learning models for resource optimization by,
processing each task by using a data pre-processing technique, to compute a transformed training data based on at least one of the training data, the number of iterations, and the number of parallel processes (p) queued on each CPU; and
training by using an asynchronous model training technique, the set of deep learning models on each GPU asynchronously with the transformed training data based on a set of asynchronous model parameters, wherein training the set of deep learning models on each GPU with the transformed training data using the asynchronous model training technique comprises:
obtaining the set of asynchronous model parameters and initializing an empty list of processed files, and a count of processed files to zeros; and
checking the count of processed files is not equal to the number of iterations and iteratively perform when the number of iterations are processed by,
scanning for a new training data file to a specified path based on the flag status and if the new training data file is detected determine the file processing status;
iteratively scanning for the new training data files for processing in the writing mode and mark as processed files, and update the new training data file;
loading the new training data file with the transformed training data; and
training a set of deep learning models on each GPU with parallel processes (q) queued on the GPU with the transformed training data and its corresponding weights and save the set of deep learning models.
|