| CPC G06F 40/295 (2020.01) [G06F 40/30 (2020.01); G06N 20/00 (2019.01); G06F 40/284 (2020.01)] | 20 Claims |
|
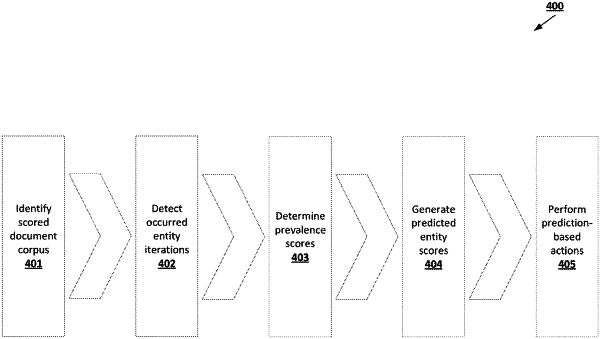
1. A computer-implemented method comprising:
identifying, by one or more processors, an entity data object associated with an input document data object using an extractive list data object associated with the entity data object and generated by:
(i) receiving, using a structured text extraction machine learning model, a structured text representation for a target document element of a training document data object,
(ii) receiving, using a structured text embedding machine learning model, an element-wise embedding based at least in part on the structured text representation for the target document element,
(iii) determining an element-wise embedding similarity measure for the element-wise embedding and a master list embedding associated with a historical extractive list data object, and
(iv) in response to determining that the element-wise embedding similarity measure satisfies an element-wise embedding similarity measure threshold, updating the historical extractive list data object with the structured text representation;
generating, by the one or more processors and using an entity scoring machine learning model, a predicted entity score for the entity data object with respect to one or more target sections of the input document data object; and
initiating, by the one or more processors, the performance of a prediction-based action based at least in part on the predicted entity score.
|