| CPC H04N 5/278 (2013.01) [G09B 21/009 (2013.01); H04L 61/4594 (2022.05); H04L 65/1069 (2013.01); H04L 65/60 (2013.01); H04L 67/561 (2022.05); H04M 1/72478 (2021.01); H04N 7/141 (2013.01); H04N 7/147 (2013.01); H04M 1/2757 (2020.01)] | 20 Claims |
|
1. A method to transcribe videos, the method comprising:
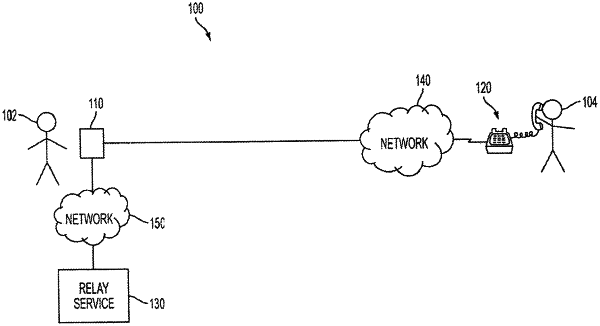
participating, by a transcription system, in a first communication session between a media system and the transcription system separate from the media system;
obtaining, at the transcription system from the media system as part of the first communication session, video that includes video data and audio data, the video provided to the transcription system from the media system and to a plurality of communication devices separate from the media system and the transcriptions system, the video obtained by the plurality of communication devices not passing through the transcription system;
generating, by the transcription system, text data based on the audio data using speech recognition software, the text data including a transcription of the audio data;
participating, by the transcription system, in a plurality of second communication sessions between the transcription system and the plurality of communication devices, the first communication session being separate from the plurality of second communication sessions; and
after generating the text data, directing, from the transcription system, the text data over the plurality of second communication sessions to the plurality of communication devices for presentation of the text data by the plurality of communication devices concurrently with presentation of the video by the plurality of communication devices in real-time.
|