| CPC G16C 20/10 (2019.02) [G06F 3/0482 (2013.01); G06F 18/2113 (2023.01); G06N 3/08 (2013.01); G06N 5/01 (2023.01); G06N 20/00 (2019.01); G16C 20/70 (2019.02); G16C 20/80 (2019.02)] | 17 Claims |
|
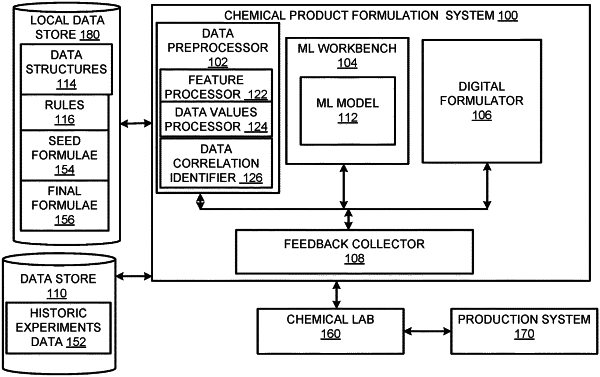
1. A chemical product formulation system comprising:
at least one processor;
a non-transitory, processor-readable medium storing machine-readable instructions that cause the at least one processor to:
access historical experiments data from a data store, wherein the historical experiments data includes data regarding experiments for synthesis of a chemical product, the historical experiments data including ingredients used for making the chemical product, proportions of the ingredients required to make the chemical product and specifications associated with each of the experiments;
identify features from the historical experiments data, wherein the features include at least attributes of the chemical product to be synthesized;
train a product-specific machine learning (ML) model on the historical experiments data to generate feature importance scores for the features,
wherein the product-specific ML model is trained via supervised learning on the historical experiments data of the chemical product to be synthesized;
obtain a feature importance score of each of the features from predictions of the product-specific machine learning (ML) model;
select a subset of the features including independent and dependent features based on the feature importance scores;
build data structures including at least a classification tree that encodes data pertaining to the subset of the features, wherein the classification tree includes a root node and child nodes,
wherein the subset of features are assigned to the root nodes and child nodes based on a cost function that evaluates splits in feature selection;
extract node attributes of the root node and the child nodes, wherein the node attributes include at least corresponding quantitative ranges associated with the subset of features, and the node attributes are extracted by applying at least natural language processing (NLP) and expression matching;
group the node attributes based on a target state, wherein the target state includes one of a process or a product criteria to be achieved during the synthesis of the chemical product;
generate a rules database on the non-transitory, processor-readable medium, the rules database is generated automatically from the data structures and the rules database stores the node attributes grouped by the target state as rules for synthesizing the chemical product, wherein the rules database includes at least columns for a rule number, the target state, ingredients for producing the chemical product, units for quantities of the ingredients and mathematical operators setting permissible ranges for the quantities, wherein the mathematical operators are included per the quantitative ranges in the node attributes;
generate seed formulae for the synthesis of the chemical product from the rules, wherein the seed formulae include at least ingredients and quantities of the ingredients to be used for the synthesis of the chemical product;
cause a display of the seed formulae on a formulation graphical user interface (GUI),
wherein the display of the seed formulae is enabled for user selections of the quantities of the ingredients within the permissible ranges set by the mathematical operators, and
the permissible ranges are further restrained to values compliant with the regulations of a selected jurisdiction associated with production of the chemical product;
receive, via the formulation GUI, user selections for specific quantities for one or more of the ingredients;
store within the non-transitory, processor-readable medium as intermediate formulae, the seed formula including the specific quantities of the one or more ingredients; and
provide one or more of the intermediate formulae that are validated and stored as final formulae to a production system for making the chemical product.
|