| CPC G10L 17/06 (2013.01) [G10L 17/02 (2013.01); G10L 17/18 (2013.01); G10L 21/0272 (2013.01); G10L 21/0308 (2013.01)] | 12 Claims |
|
1. An apparatus for processing speech data, the apparatus comprising:
a memory storing instructions; and
a processor configured to execute the instructions to:
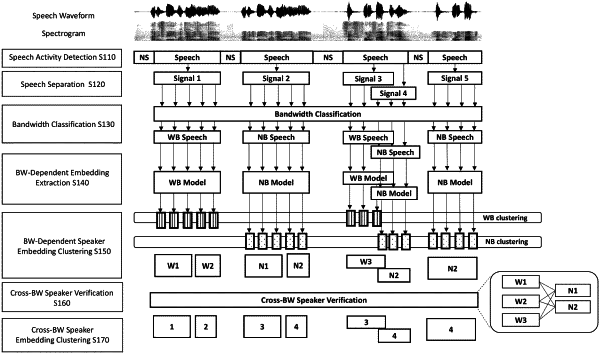
separate an input speech into speech signals;
identify a bandwidth of each of the speech signals;
obtain speaker embeddings from each of a plurality of different speech embedding extraction models by inputting the speech signals having different bandwidths to the different speech embedding extraction models, wherein at least one neural network of each of the plurality of different speech embedding extraction models is trained based on the different bandwidths;
cluster the speaker embeddings for each of the different bandwidths separately, to obtain bandwidth-dependent embedding clusters for each of the different bandwidths; and
combine the bandwidth-dependent embedding clusters based on a vector dissimilarity between the bandwidth-dependent clusters, to obtain cross-bandwidth embedding clusters as speaker clusters, each of the speaker clusters corresponding to a speaker identity,
wherein each of the plurality of different speech embedding extraction models comprises a plurality of frame-level layers, a pooling layer, a plurality of segmentation-level layers, and an output layer; and
wherein the processor is further configured to obtain the speaker embeddings by inputting bandwidth information to one of the plurality of frame-level layers, and to the plurality of segment-level layers.
|