| CPC G10L 15/28 (2013.01) [G10L 15/16 (2013.01)] | 20 Claims |
|
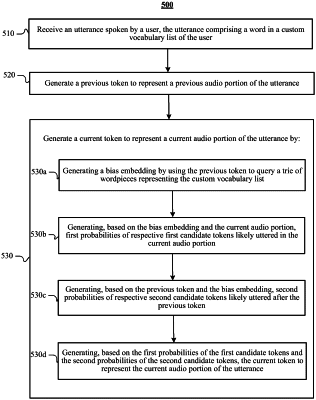
1. A method comprising, by a computing system:
receiving an utterance spoken by a user, the utterance comprising a word in a custom vocabulary list of the user;
generating a previous token to represent a previous audio portion of the utterance; and
generating a current token to represent a current audio portion of the utterance by:
generating a bias embedding by using the previous token to query a trie of wordpieces representing the custom vocabulary list, wherein the trie is based on biasing words;
generating, based on the bias embedding and the current audio portion, first probabilities of respective first candidate tokens likely uttered in the current audio portion;
generating, based on the previous token and the bias embedding, second probabilities of respective second candidate tokens likely uttered after the previous token; and
generating, based on the first probabilities of the respective first candidate tokens and the second probabilities of the respective second candidate tokens, the current token to represent the current audio portion of the utterance.
|