| CPC G10L 15/18 (2013.01) [G06F 16/3329 (2019.01); G10L 15/22 (2013.01); G06N 5/022 (2013.01); G10L 2015/081 (2013.01); G10L 2015/088 (2013.01)] | 20 Claims |
|
1. A computing system, comprising:
a processor; and
memory storing instructions that, when executed by the processor, cause the processor to perform acts comprising:
obtaining features that have been extracted from an acoustic signal, wherein the acoustic signal is based upon spoken words uttered by a user, and further wherein the spoken words are indicative of a query that is to be transmitted to a search engine;
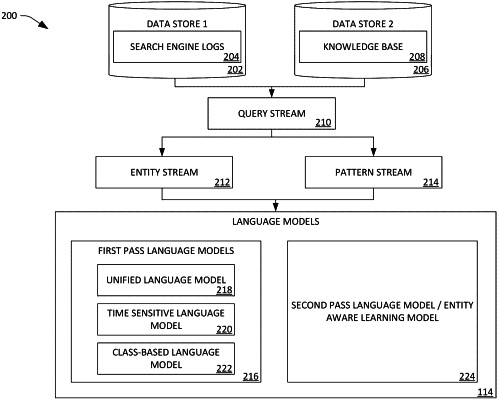
performing automatic speech recognition (ASR) based upon the features and a language model (LM), wherein the LM comprises a plurality of first pass LMs and a second pass LM, wherein the plurality of first pass LMs output a list of word sequences and probabilities of the word sequences, wherein the second pass LM revises the probabilities of the word sequences, and wherein the LM has been generated based upon expanded pattern data, the expanded pattern data comprising a name of an entity and a search term, wherein the entity belongs to a segment identified in a knowledge base, the segment categorizing the entity;
identifying a most likely sequence of words corresponding to the features based upon results of the ASR; and
outputting computer-readable text to the search engine, the text comprising the most likely sequence of words.
|