| CPC G10L 15/04 (2013.01) [G06F 40/284 (2020.01); G06N 3/04 (2013.01); G10L 15/063 (2013.01); G10L 15/16 (2013.01); G10L 25/30 (2013.01); G10L 15/02 (2013.01)] | 18 Claims |
|
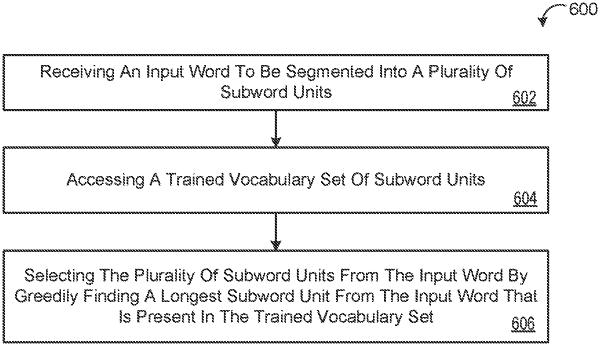
1. A computer-implemented method when executed on data processing hardware causes the data processing hardware to perform operations comprising:
receiving an input word to be segmented into a plurality of subword units; and
executing a subword segmentation routine to segment the input word into a plurality of subword units by:
accessing a trained vocabulary set of subword units; and
selecting the plurality of subword units from the input word by greedily finding a longest subword unit from the input word that is present in the trained vocabulary set until an end of the input word is reached, wherein selecting the plurality of subword units comprises, for each corresponding position of a plurality different positions of the input word:
identifying all possible candidate subword units from the input word at the corresponding position that are present in the trained vocabulary set; and
randomly sampling from all of the possible candidate subword units by assigning a 1−p probability to a longest one the possible candidate subword units and dividing a rest of the p probability evenly among all of the possible candidate subword units from the input word at the corresponding position.
|