| CPC G10L 15/005 (2013.01) [G10L 15/01 (2013.01); G10L 15/02 (2013.01); G10L 15/22 (2013.01); G10L 15/32 (2013.01); G10L 25/78 (2013.01)] | 20 Claims |
|
1. A method comprising:
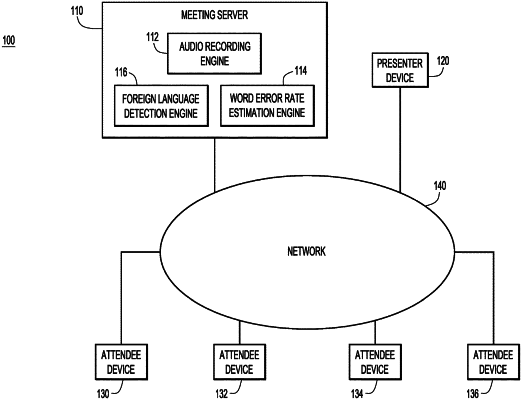
generating, from a plurality of audio datasets associated with captured audio via a plurality of automatic speech recognition engines, a plurality of outputs, wherein each of the plurality of automatic speech recognition engines is configured to recognize speech of a same first language;
determining, via a word error estimation engine from the plurality of outputs of the plurality of automatic speech recognition engines, a plurality of word error rate estimates that comprise at least one word error rate estimate for each of the plurality of audio datasets of a word error rate in the same first language; and
determining, from the plurality of word error rate estimates via a foreign language detection model, that audio in the plurality of audio datasets includes speech in a second language which differs from the first language that each of the plurality of automatic speech recognition engines is configured to recognize, wherein the foreign language detection model comprises one or more of a vector machine, a neural network or a boosted tree model trained to determine that an audio dataset language differs from an automatic speech recognition engine language based on word error rate estimates.
|