| CPC G10L 13/047 (2013.01) | 22 Claims |
|
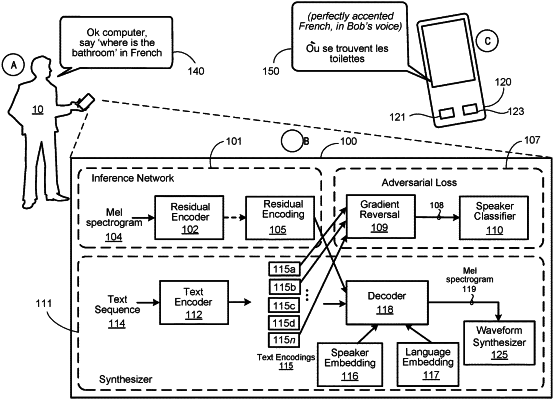
1. A computer-implemented method that when executed on data processing hardware causes the data processing hardware to perform operations comprising:
receiving an input text sequence in a first language;
obtaining a speaker embedding specifying specific voice characteristics of a target speaker for synthesizing the input text sequence into speech that clones a voice of the target speaker; and
processing, using a multilingual text-to-speech (TTS) model configured to receive the speaker embedding and the input text sequence in the first language as input, the speaker embedding and the input text sequence in the first language to generate an output audio feature representation as output from the multilingual TTS model, the output audio feature representation representing synthesized speech that clones the voice of the target speaker in a second language different than the first language.
|