| CPC G10L 13/02 (2013.01) [G06N 3/08 (2013.01); G10L 17/18 (2013.01); G10L 21/013 (2013.01); G10L 21/10 (2013.01)] | 16 Claims |
|
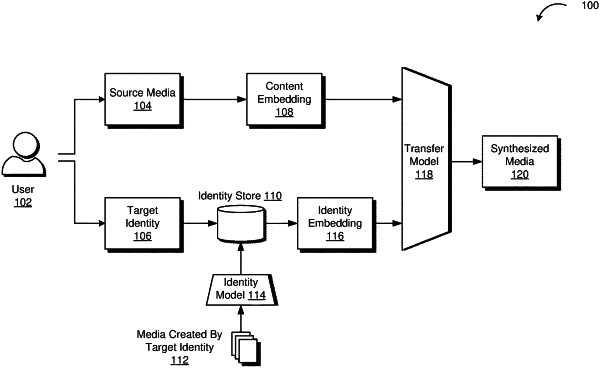
1. A computer-implemented method, comprising:
obtaining a plurality of audio samples of songs associated with respective identities;
determining, based on the plurality of audio samples of songs and using a first encoder, multiple voice identity embeddings for the respective identities, including a first voice identity embedding associated with the first identity;
recording a first audio data sample from a user;
determining a second voice identity embedding for the user based on the first audio data;
storing, in an identity store, the multiple voice identity embeddings associated with the respective identities, including the first voice embedding for the first identity;
obtaining a request, from the user, to generate synthesized song audio, wherein the request specifies:
audio song content associated with a second identity; and
the first identity, wherein the first identity corresponds to the user, and the first voice identity embedding in the identity store is based on the first audio data;
determining a spectrogram of the audio song content;
determining, based on the spectrogram and using a second encoder, a content embedding associated with the audio song content; and
generating, using a second decoder corresponding to the second encoder and based on the first voice identity embedding and the content embedding, the synthesized song audio.
|