| CPC G06V 20/41 (2022.01) [G06N 3/045 (2023.01); G06N 3/08 (2013.01); G06Q 30/0276 (2013.01); G06V 10/25 (2022.01); G06V 20/46 (2022.01); G06V 30/32 (2022.01); G06V 2201/07 (2022.01)] | 12 Claims |
|
1. A method comprising:
generating, by a computing device, a target video from multiple original files, the multiple original files including at least picture files and text files, the generating comprising:
obtaining, by the computing device, the multiple original files, each of the multiple original files including at least one subject matter;
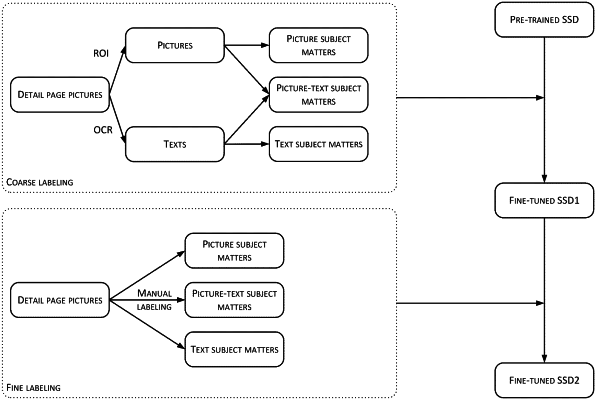
extracting, by the computing device, multiple subject matters and labeling information corresponding to the multiple subject matters from the multiple original files, wherein extracting the labeling information corresponding to the multiple subject matters from the multiple original files comprises: extracting the labeling information corresponding to the multiple subject matters from the multiple original files using a first target neural network model, and wherein extracting the multiple subject matters from the multiple original files comprises:
combining, by the computing device, a picture block and a text block based on layout rules, wherein combining the picture block and the text block based on layout rules comprises:
combining, by the computing device, the picture block and the text block into a picture-text subject matter when the text block is located in a first preset area inside the picture block and a proportion of an inside part of the picture block that the text block accounts for is greater than a first preset threshold;
combining, by the computing device, the picture block and the text block into the picture-text subject matter when the text block is located in a second preset area outside the picture block and a distance between the text block and the picture block is less than a second preset threshold;
ignoring, by the computing device, a text in the picture block if the text block accounts for less than a third preset percentage of an image in the picture block; and
ignoring, by the computing device, the image in the picture block if the text block accounts for greater than a fourth preset percentage of the image;
determining, by the computing device, a display order of each subject matter of the multiple subject matters based at least in part on the labeling information;
establishing, by the computing device, a display structure corresponding to the multiple subject matters based on the labeling information, the display structure including a graph structure having hierarchical and ordering information for text and picture reconstruction, wherein establishing the display structure corresponding to the multiple subject matters based on the labeling information comprises:
establishing the display structure corresponding to the multiple subject matters based on the labeling information and a second target neural network model, wherein establishing the display structure corresponding to the multiple subject matters based on the labeling information and the second target neural network model comprises:
performing clustering processing on the multiple subject matters based on the labeling information and the second target neural network model to obtain multiple subject matter sub-categories; and
performing ordering determination on each of the multiple subject matter sub-categories to obtain the display structure; and
combining, by the computing device, the multiple subject matters using the display structure to generate the target video.
|