| CPC G06Q 30/0603 (2013.01) [G06F 40/284 (2020.01); G06Q 30/0625 (2013.01); G06Q 30/0631 (2013.01)] | 20 Claims |
|
1. A system, comprising:
one or more processors and one or more memories to store computer-executable instructions that, if executed, cause the one or more processors to:
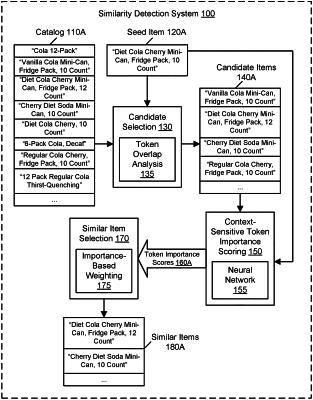
generate training data for one or more machine learning models, the training data comprising a plurality of respective contexts for a plurality of seed items, wherein individual contexts of the plurality of respective contexts comprise a respective plurality of tokens from a corresponding textual description of the respective seed item in an electronic catalog;
determine, for individual seed items of the plurality of seed items, a respective subset of items from the electronic catalog to be similar to the individual seed item based on a comparison of the corresponding textual description of the individual seed item to textual descriptions of items in the electronic catalog;
calculate respective token importance scores for individual tokens of the individual contexts, wherein for individual ones the plurality of seed items, the respective token importance scores are calculated for respective individual tokens of the respective context for the individual seed item based on a frequency of occurrence of the individual token across the corresponding textual description of the individual seed item and textual descriptions of the subset of items determined to be similar to the individual seed item;
assign the calculated respective token importance scores to the corresponding individual tokens of the respective contexts in the training data, where a same token is assigned a different importance score in different contexts due to the same token having different frequencies of occurrence for the different contexts and corresponding subsets of items determined to be similar;
train, based on the training data comprising the plurality of respective contexts having the respective pluralities of tokens and the calculated token importance scores assigned in the training data to the respective tokens specific to each context, the one or more machine learning models to determine respective token importance scores for an individual token based on respective contexts in which the individual tokens appear;
select a plurality of candidate items with respect to another seed item from the electronic catalog, wherein the electronic catalog comprises textual descriptions of the plurality of candidate items, and wherein the plurality of candidate items are selected based at least in part on a comparison of tokens in the textual descriptions of the plurality of candidate items to tokens in a textual description of the other seed item;
determine, using the trained one or more machine learning models, respective token importance scores for at least a portion of the tokens in the textual description of the other seed item from the electronic catalog;
determine respective similarity scores for at least a portion of the plurality of candidate items with respect to the other seed item, wherein the respective similarity scores are determined using a plurality of weights based at least in part on the respective token importance scores determined using the trained one or more machine learning models to weight a token similarity comparison between tokens for the other seed item and tokens for the plurality of candidate items;
select, from the plurality of candidate items, a set of similar items to the other seed item based at least in part on the respective similarity scores; and
generate a user interface element descriptive of at least some of the set of similar items, wherein the user interface element is displayed in a user interface associated with the electronic catalog.
|