| CPC G06N 3/084 (2013.01) [G06F 16/00 (2019.01); G06F 16/335 (2019.01); G06N 3/045 (2023.01); G06N 5/04 (2013.01); G06N 3/044 (2023.01)] | 14 Claims |
|
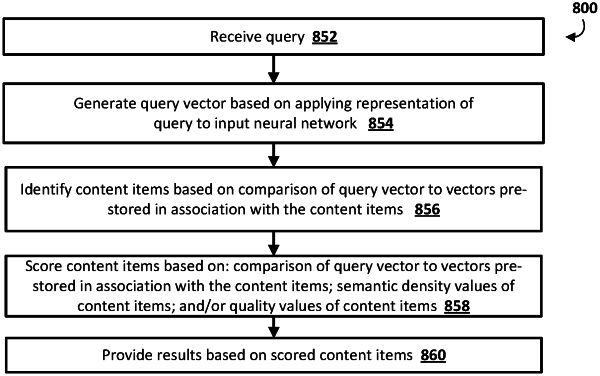
1. A method implemented by one or more processors, the method comprising:
receiving a textual query generated based on user interface input provided by a user via a client device of the user, the textual query comprising multiple words;
generating a query representation, of the textual query, that is an embedding of two or more of the multiple words, wherein generating the query representation is based on applying the two or more of the multiple words to an embedding model;
applying the query representation of the textual query to a trained input neural network model, the trained input neural network model being different from the embedding model;
generating one query vector over the trained input neural network model based on applying the query representation to the trained input neural network model;
determining a relevance value that indicates relevance of a content item to the query, wherein determining the relevance value comprises:
determining the relevance value based on a dot product of the query vector to one vector stored in association with the content item, the one vector being stored in association with the content item prior to receiving the query and being previously generated based on applying a content representation to a separate subsequent content neural network model, the content representation being based on multiple content words of the content item; and
based on the relevance value, providing to the client device a result that is based on the content item, the result provided in response to receiving the textual query.
|