| CPC G06N 3/08 (2013.01) [G06N 3/088 (2013.01); Y04S 10/50 (2013.01)] | 20 Claims |
|
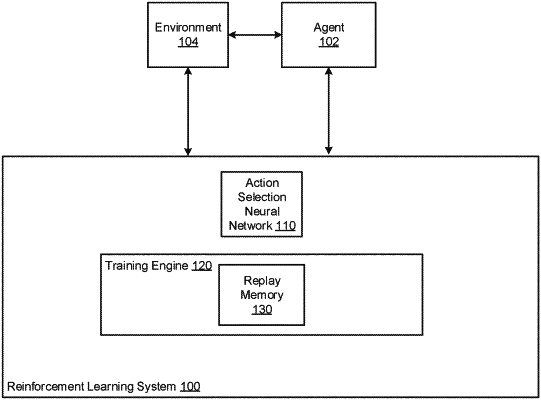
1. A method for controlling an agent in an environment to perform a task, the method comprising:
receiving a current observation characterizing a current state of the environment;
processing the current observation using a neural network to generate an output that specifies an action to be performed by the agent in response to the current observation, wherein the neural network has been trained through reinforcement learning to determine trained values of parameters of the neural network using a plurality of pieces of selected experience data selected from a prioritized experience memory that stored, during the training of the neural network through reinforcement learning, a plurality of pieces of experience data in association with expected learning progress measures,
wherein each piece of experience data is a training tuple that comprises a training current observation characterizing a training current state of the environment, and a training current action performed by the agent in response to the training current observation, and wherein, for each piece of experience data, a respective value of an expected learning progress measure that is stored in association with the piece of experience data in the prioritized experience memory is derived from a result of a preceding time that values of the parameters of the neural network were updated using the piece of experience data during the training, and
wherein, during the training, the plurality of pieces of selected experience data were selected from the prioritized experience memory based on the respective values of the expected learning progress measures that are stored in association with the plurality of pieces of experience data in the prioritized experience memory; and
causing the agent to perform the action specified by the output in response to the current observation.
|