| CPC G06N 3/08 (2013.01) [G06F 18/2113 (2023.01); G06N 20/00 (2019.01)] | 21 Claims |
|
1. A method performed by one or more computers, the method comprising:
receiving a request for an output sequence through a dialog system;
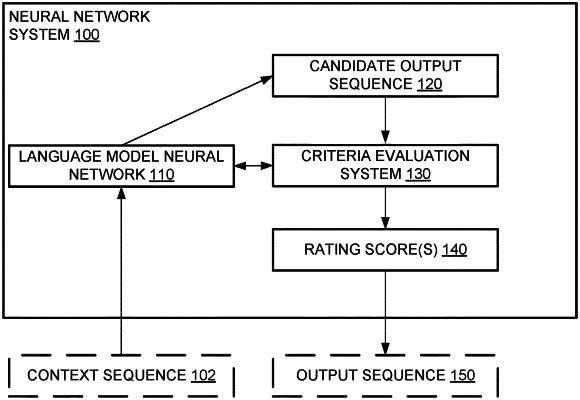
processing an input sequence according to the request to generate, using an auto-regressive language model neural network, a first candidate output sequence, wherein the first candidate output sequence comprises a plurality of tokens that are each selected from a vocabulary of tokens, wherein the auto-regressive language model neural network includes (i) a sequence of attention blocks, each attention block of the sequence of attention blocks including one or more network layers configured to generate hidden states for the plurality of tokens in the first candidate output sequence, the generation comprising applying a self-attention mechanism to process the input sequence, and (ii) an output subnetwork configured to process an output of a last attention block of the sequence of attention blocks to generate a respective score for each token of the vocabulary of tokens;
for each output sequence criterion in a set of one or more output sequence criteria:
processing, using the auto-regressive language model neural network, a new input sequence comprising (i) the first candidate output sequence followed by (ii) a sequence of tokens of the vocabulary of tokens that specify the output sequence criterion to generate a respective new score for each token in the vocabulary of tokens, wherein the sequence of tokens of the vocabulary of tokens that specify the output sequence criterion comprises multiple tokens representing a natural language description of the output sequence criterion, wherein the output sequence criterion measures a respective property of the first candidate output sequence, and wherein generating the respective new scores comprises:
processing the sequence of tokens of the vocabulary of tokens using corresponding attention blocks of the sequence of attention blocks, the processing comprising: for each of the one or more network layers in the corresponding attention blocks, re-using the hidden states generated as output by the network layer for the plurality of tokens in the first candidate output sequence, without processing the plurality of tokens in the first candidate output sequence using the network layer, to generate the respective new score for each token in the vocabulary of tokens;
identifying a subset of the vocabulary of tokens for the output sequence criterion; and
determining, from the respective new scores for tokens that are in the subset of the vocabulary of tokens, a respective rating score for the first candidate output sequence that represents a degree to which the first candidate output sequence generated by the auto-regressive language model neural network satisfies the output sequence criterion; and
displaying, on a user interface associated with the dialog system, the first candidate output sequence as an output from the dialog system corresponding to the request based on the respective rating scores determined for the first candidate output sequence with respect to the one or more output sequence criteria.
|