| CPC G06N 3/08 (2013.01) [G06N 3/063 (2013.01)] | 3 Claims |
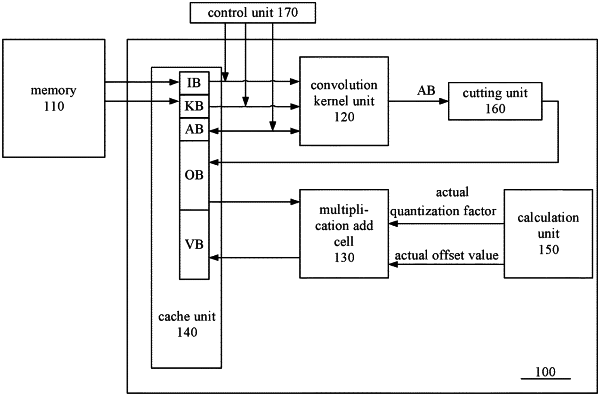
|
1. A data dividing method applied to a convolution operation and performed by a processor, comprising:
determining a restriction condition in connection with performing of the convolution operation;
determining a dividing size for each dimension corresponding to each data according to the restriction condition;
dividing each of the dimensions corresponding to each data according to the dividing size to obtain a set of candidate sub-data blocks for each of the dimensions corresponding to each data;
combining each candidate sub-data block in the set of candidate sub-data blocks for each dimension with each candidate sub-data block in the sets of candidate sub-data blocks for other dimensions to obtain a set of candidate data blocks for each data; and
inputting each of the sets of the candidate data blocks into a preset cost function, respectively, and selecting the candidate data block corresponding to a smallest output value of the cost function as a target data block, and using the target data block as the dividing method of the data;
wherein the restriction condition comprises the number of parallel channels and the number of memory units in the on-chip memory allocated for each data;
wherein the step of inputting each of the sets of candidate data blocks into the preset cost function, respectively, comprises:
removing invalid candidate data blocks from each of the sets of candidate data blocks according to the number of memory units allocated for each data to obtain a set of valid candidate data blocks; and
inputting each of the sets of valid candidate data blocks into the cost function, respectively;
wherein the step of inputting each of the sets of valid candidate data blocks into the cost function, respectively, comprises:
determining a valid candidate data block combination for each valid candidate data block in the set of valid candidate data blocks according to an order of the dimensions of the convolution operation to obtain a set of valid candidate data block combinations for each data; and
inputting each of the sets of valid candidate data block combinations into the cost function, respectively.
|