| CPC G06N 3/063 (2013.01) [G06F 9/3887 (2013.01); G06N 3/04 (2013.01); G06N 3/08 (2013.01); G06N 5/046 (2013.01); G06N 20/00 (2019.01); G06T 1/20 (2013.01)] | 20 Claims |
|
1. An apparatus, comprising:
at least one processor to perform operations to implement a neural network; and
a graphics processing unit (GPU) including circuitry configured to accelerate neural network computations, the circuitry comprising:
processing circuitry configured to perform general-purpose graphics computations, the processing circuitry including a single instruction multiple thread (SIMT) architecture;
a local memory to store one or more graph representations associated with a neural network, the one or more graph representations to indicate node adjacency for the neural network;
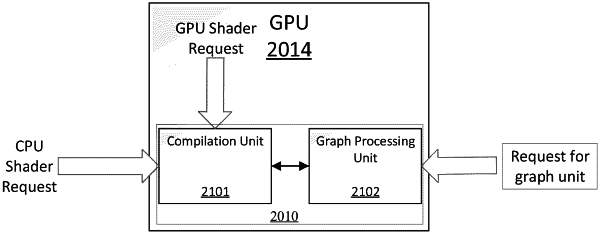
a graph processing unit (GrPU) including instruction execution circuitry configured to accelerate computations on the one or more graph representations in response to a request from the processing circuitry, wherein the GrPU includes multiple single instruction multiple data (SIMD) hardware threads to concurrently traverse multiple graph representations and execute instructions associated with the multiple graph representations;
a compilation unit (CU) including instruction execution circuitry configured to dynamically compile shader kernels locally on the GPU; and
wherein the GrPU is configured to perform a compute operation implemented via a dynamically compiled shader, the dynamically compiled shader is dynamically compiled by the CU and executed by the GrPU in response to a condition detected by the GPU, the condition associated with input data of a neural network computation.
|