| CPC G06F 8/313 (2013.01) [G06F 8/47 (2013.01); G06F 12/0646 (2013.01); G06N 3/04 (2013.01); G06N 20/00 (2019.01)] | 17 Claims |
|
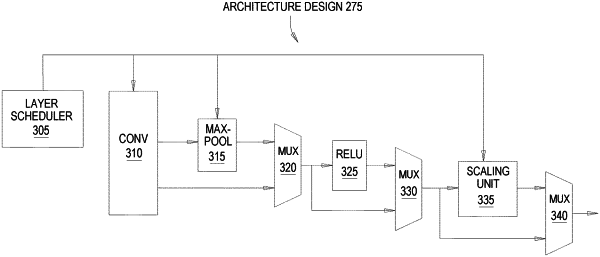
1. A method for generating a neural network accelerator, the method comprising:
receiving a neural network model comprising software code defining an architecture design, wherein the architecture design represents a plurality of functional blocks where conditional logic is disposed between each of the plurality of functional blocks for executing a plurality of layers in a neural network, wherein each of the plurality of functional blocks is software code in a different respective software class and wherein the conditional logic receives, as a first input, an output of a prior functional block and, as a second input, a bypass path that bypasses the prior functional block, and the conditional logic determines whether to forward either the first input or the second input to a subsequent functional block, wherein a first functional block is upstream of the first input, the second input, and the prior functional block, and the first functional block transmits data to (i) the second input of the conditional logic via the bypass path, and (ii) the prior functional block;
receiving a value of a template parameter, wherein the template parameter controls an execution of at least one of the plurality of functional blocks, and wherein the value of the template parameter is separate from the software classes of the plurality of functional blocks; and
compiling, using one or more computing processors, the software code in the neural network model into a hardware design that implements the neural network accelerator in a hardware system, wherein during compilation, the value of the template parameter is used as an argument in one of the respective software classes.
|