| CPC G06F 40/106 (2020.01) | 14 Claims |
|
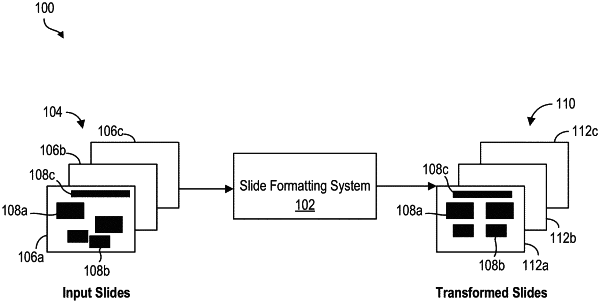
1. A method for automatic formatting of presentation slides, comprising:
receiving an input slide comprising one or more slide objects, wherein the input slide has a first slide layout configuration;
determining metadata associated with the input slide, the determined metadata comprising property features of the one or more slide objects;
analyzing the metadata to detect the one or more slide objects;
determining one or more slide layout functional objectives;
based on the one or more slide layout functional objectives, applying one or more transformations to the detected slide objects, wherein each transformation comprises modifying the metadata corresponding to the one or more detected slide objects to generate a corresponding one or more transformed slide objects, each detected slide object being associated with a corresponding transformed slide object; and
generating a transformed output slide, the transformed output slide comprising the one or more generated transformed slide objects, the transformed output slide having a second slide layout configuration,
wherein analyzing the metadata to detect the one or more slide objects comprises applying one or more trained slide object detection models;
wherein the one or more slide object detection models receive inputs comprising property features and derived property features associated with one or more slide objects, and the derived property features are determined from the one or more property features associated with the one or more slide object; and
wherein the one or more slide object detection models comprise one or more table detection models, and analyzing the metadata using the one or more table detection models comprises:
applying pair-wise column and row prediction models;
generating column and row graph representations;
extracting column and row graph features from the column and row graph representations;
applying a trained object-in-table detection prediction model to each slide object to generate a first prediction variable;
applying an object-in table position model to each slide object to generate a second prediction variable; and
generating an output classification vector comprising the first and second prediction variables.
|