| CPC G06F 21/32 (2013.01) [G06F 18/213 (2023.01); G06F 18/214 (2023.01); G06F 21/6245 (2013.01)] | 18 Claims |
|
1. A system comprising:
one or more memories, storing first computer-executable instructions; and
one or more hardware processors to execute the first computer-executable instructions to:
at a first time:
retrieve an input image from the one or more memories;
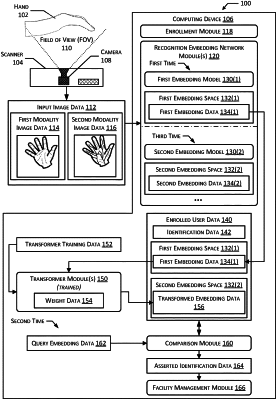
generate, using a first embedding model and the input image, first embedding data within a first embedding space;
store the first embedding data in the one or more memories; and
remove the input image from the one or more memories;
at a second time:
determine a second embedding model, wherein the second embedding model generates second embedding data within a second embedding space, wherein the second embedding space is different from the first embedding space;
determine training input data comprising:
a plurality of images, wherein each image of the plurality of images is associated with a sample identifier that indicates a training identity associated with the each image;
determine transformer training data comprising:
the sample identifier associated with the each image;
first training embedding data using the first embedding model and based on the each image, wherein the first training embedding data is associated with the first embedding space; and
second training embedding data using the second embedding model and based on the each image, wherein the second training embedding data is associated with the second embedding space;
determine first transformed embedding data using a transformer network and based on the first training embedding data;
determine a first classification loss based on the first transformed embedding data;
determine a second classification loss based on the second training embedding data;
determine a similarity loss based on the first transformed embedding data and the second training embedding data;
determine a divergence loss based on the first classification loss and the second classification loss; and
train the transformer network based on the first classification loss, the second classification loss, the similarity loss, and the divergence loss; and
at a third time:
retrieve the first embedding data from the one or more memories;
transform, using the transformer network, the first embedding data into second transformed embedding data in the second embedding space;
retrieve query embedding data in the second embedding space; and
compare the query embedding data with the second transformed embedding data.
|