| CPC G06F 16/24575 (2019.01) | 10 Claims |
|
1. A method comprising:
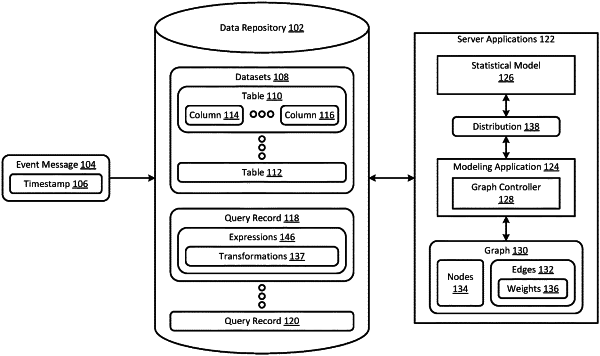
processing a set of query texts to identify a set of expressions, wherein each expression of the set of expressions identifies a set of columns of datetime data in a datastore, wherein each data in the datetime data comprises a timestamp;
training a statistical model to generate a trained statistical model,
wherein the statistical model is a kernel density estimation model that is adapted to train a neural network with the datetime data in the set of columns of datetime data to generate a kernel function, and
wherein the kernel function includes bandwidth and amplitude parameters for the kernel density estimation model;
determining, by the trained statistical model executing on a computer processor, a distribution of the datetime data for each column of datetime data that was identified, wherein the distribution of the datetime data is skewed to a local daytime;
processing the set of expressions to generate a directed graph comprising a plurality of nodes and a plurality of edges, wherein each node represents one column of the set of columns of datetime data, or a transformation applied by one expression of the set of expressions to the one column of the set of columns of datetime data, and each edge represents a relationship between two nodes, wherein the relationship corresponds to an expression of the set of expressions or the one expression of the set of expressions; and
generating a weight for each edge of the plurality of edges of the directed graph according to the distribution of the datetime data in the columns represented by the two nodes corresponding to each edge and a usage index of a corresponding expression of the set of expressions, comprising:
for each edge of the plurality of edges, determining a data shift for the distribution of the datetime data in the columns represented by the two nodes corresponding to the edge based on the corresponding expression of the set of expressions;
for each edge of the plurality of edges, counting a number of unique users that submitted a query including the corresponding expression of the set of expressions, and assigning normalized scores to the unique users based on respective query histories of the unique users to generate the usage index of the corresponding expression of the set of expressions; and
weighting each edge of the plurality of edges according to the usage index and the data shift.
|