| CPC C12N 15/1131 (2013.01) [A61P 31/20 (2018.01); A61K 31/713 (2013.01); C12N 2310/14 (2013.01); C12N 2310/315 (2013.01); C12N 2310/321 (2013.01); C12N 2310/322 (2013.01); C12N 2310/344 (2013.01); C12N 2310/351 (2013.01); C12N 2320/32 (2013.01)] | 18 Claims |
|
1. A siRNA conjugate comprising siRNA and a conjugating group conjugated to the siRNA, and having a structure as shown by Formula (308):
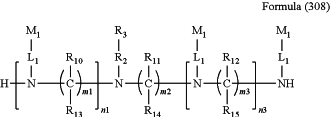 wherein n1 is an integer of 1-2, and n3 is an integer of 0-[4]1, and n1+n3=2-3;
m1, m2, and m3 independently of one another are an integer of 2-10;
R10, R11, R12, R13, R14 and R15 independently of one another are H, or selected from the group consisting of C1-C10 alkyl, C1-C10 haloalkyl, and C1-C10 alkoxy;
R3 is a group having a structure as shown by Formula (A59):
 wherein E1 is OH, SH or BH2; Nu is siRNA;
R2 is a linear alkylene of 1 to 20 carbon atoms in length, wherein one or more carbon atoms are optionally replaced with one or more groups selected from the group consisting of: C(O), NH, O, S, CH═N, S(O)2, C2-C10 alkenylene, C2-C10 alkynylene, C6-C10 arylene, C3-C18 heterocyclylene, and C5-C10 heteroarylene, and wherein R2 optionally has one or more substituents selected from the group consisting of: C1-C10 alkyl, C6-C10 aryl, C5-C10 heteroaryl, C1-C10 haloalkyl, —OC1-C10 alkyl, —OC1-C10 alkylphenyl, —C1-C10 alkyl-OH, —OC1-C10 haloalkyl, —SC1-C10 alkyl, —SC1-C10 alkylphenyl, —C1-C10 alkyl-SH, —SC1-C10 haloalkyl, halo, —OH, —SH, —NH2, —C1-C10 alkyl-NH2, —N(C1-C10 alkyl)(C1-C10 alkyl), —NH(C1-C10 alkyl), cyano, nitro, —CO2H, —C(O)O(C1-C10 alkyl), —CON(C1-C10 alkyl)(C1-C10 alkyl), —CONH(C1-C10 alkyl), —CONH2, —NHC(O)(C1-C10 alkyl), —NHC(O)(phenyl), —N(C1-C10 alkyl)C(O)(C1-C10 alkyl), —N(C1-C10 alkyl)C(O)(phenyl), —C(O)C1-C10 alkyl, —C(O)C1-C10 alkylphenyl, —C(O)C1-C10 haloalkyl, —OC(O)C1-C10 alkyl, —SO2(C1-C10 alkyl), —SO2(phenyl), —SO2(C1-C10 haloalkyl), —SO2NH2, —SO2NH(C1-C10 alkyl), —SO2NH(phenyl), —NHSO2(C1-C10 alkyl), —NHSO2(phenyl), and —NHSO2(C1-C10 haloalkyl);
each L1 is independently a linear alkylene of 1 to 70 carbon atoms in length, wherein one or more carbon atoms are optionally replaced with one or more groups selected from the group consisting of: C(O), NH, O, S, CH═N, S(O)2, C2-C10 alkenylene, C2-C10 alkynylene, C6-C10 arylene, C3-C18 heterocyclylene, and C5-C10 heteroarylene, and wherein L1 optionally has one or more substituents selected from the group consisting of: C1-C10 alkyl, C6-C10 aryl, C5-C10 heteroaryl, C1-C10 haloalkyl, —OC1-C10 alkyl, —OC1-C10 alkylphenyl, —C1-C10 alkyl-OH, —OC1-C10 haloalkyl, —SC1-C10 alkyl, —SC1-C10 alkylphenyl, —C1-C10 alkyl-SH, —SC1-C10 haloalkyl, halo, —OH, —SH, —NH2, —C1-C10 alkyl-NH2, —N(C1-C10 alkyl)(C1-C10 alkyl), —NH(C1-C10 alkyl), cyano, nitro, —CO2H, —C(O)O(C1-C10 alkyl), —CON(C1-C10 alkyl)(C1-C10 alkyl), —CONH(C1-C10 alkyl), —CONH2, —NHC(O)(C1-C10 alkyl), —NHC(O)(phenyl), —N(C1-C10 alkyl)C(O)(C1-C10 alkyl), —N(C1-C10 alkyl)C(O)(phenyl), —C(O)C1-C10 alkyl, —C(O)C1-C10 alkylphenyl, —C(O)C1-C10 haloalkyl, —OC(O)C1-C10 alkyl, —SO2(C1-C10 alkyl), —SO2(phenyl), —SO2(C1-C10 haloalkyl), —SO2NH2, —SO2NH(C1-C10 alkyl), —SO2NH(phenyl), —NHSO2(C1-C10 alkyl), —NHSO2(phenyl), and —NHSO2(C1-C10 haloalkyl);
 represents a site where a group is linked to the rest of the molecule; represents a site where a group is linked to the rest of the molecule;M1 represents a targeting group, wherein each of the targeting groups is independently a ligand that has affinity to asialoglycoprotein receptors (ASGP-R) on a surface of mammalian hepatocytes;
wherein the siRNA comprises a sense strand and an antisense strand, each nucleotide in the siRNA being independently a modified or unmodified nucleotide, wherein the sense strand comprises a nucleotide sequence I, and the antisense strand comprises a nucleotide sequence II;
the nucleotide sequence I and the nucleotide sequence II are at least partly reverse complementary to form a double stranded region; wherein the nucleotide sequence I comprises a nucleotide sequence A, which has the same length as the nucleotide sequence shown in SEQ ID NO: 1 with no more than 3 nucleotide differences; and the nucleotide sequence II comprises a nucleotide sequence B, which has the same length as the nucleotide sequence shown in SEQ ID NO: 2 with no more than 3 nucleotide differences:
| ||||||||||||
wherein,
Z is A; Z′ is U; and
the nucleotide sequence A comprises a nucleotide ZA at the position corresponding to Z; the nucleotide sequence B comprises a nucleotide Z′B at the position corresponding to Z′; the nucleotide Z′B is the first nucleotide at 5′ terminal of the antisense strand.
|