| CPC H04N 21/43615 (2013.01) [G06Q 10/109 (2013.01); G10L 17/22 (2013.01); H04L 12/2803 (2013.01); H04L 12/281 (2013.01); H04L 12/282 (2013.01); H04L 67/62 (2022.05); H04N 21/23418 (2013.01); H04N 21/25875 (2013.01); H04N 21/4223 (2013.01)] | 20 Claims |
|
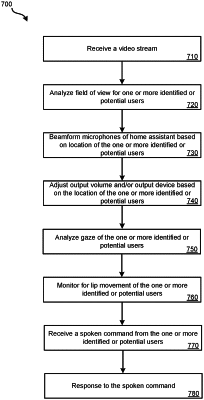
1. A method for handling spoken commands based on characteristics observed by an integrated video service, the method comprising:
receiving a video stream from a streaming video camera;
analyzing a field of view in the received video stream to determine a location for one or more identified or potential users;
beamforming audio from microphones of a home assistant device based on the location of the one or more identified or potential users;
adjusting an audio output based on the location of the one or more identified or potential users;
receiving a spoken command from the one or more identified or potential users; and
outputting a response to the spoken command.
|