| CPC G10L 21/0232 (2013.01) [G06N 3/08 (2013.01); G10L 21/0264 (2013.01); G10L 21/0332 (2013.01)] | 20 Claims |
|
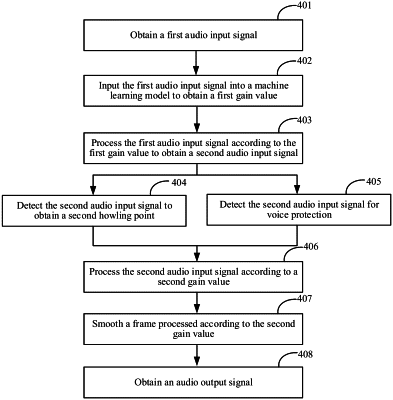
1. An audio signal processing method, performed by a terminal device, the method comprising:
obtaining a first audio input signal;
inputting the first audio input signal into a machine learning model to obtain a first howling point, and obtaining a first gain value according to the first howling point, the first howling point indicating a howling point of a frequency band corresponding to an effective audio signal in the first audio input signal, and the first gain value indicating a suppression parameter of the first howling point;
processing the first audio input signal according to the first gain value to obtain a second audio input signal;
detecting the second audio input signal to obtain a second howling point, and obtaining a second gain value according to the second howling point, the second howling point indicating a howling point of a frequency band corresponding to an ineffective audio signal in the second audio input signal; and
processing the second audio input signal according to the second gain value to obtain an audio output signal.
|