| CPC G10L 15/22 (2013.01) [G06F 40/295 (2020.01); G06F 40/30 (2020.01); G10L 15/26 (2013.01); G10L 15/065 (2013.01); G10L 15/183 (2013.01); G10L 15/197 (2013.01)] | 20 Claims |
|
1. A computer-implemented method that when executed on data processing hardware causes the data processing hardware to perform operations comprising:
receiving a transcription request for a voice input captured by a user device, the transcription request comprising audio data and context data, the audio data indicating the voice input and the context data indicating:
an application to which the voice input is directed; and
a particular stage from a multi-stage voice activity corresponding to a series of user interactions related to a task of the application;
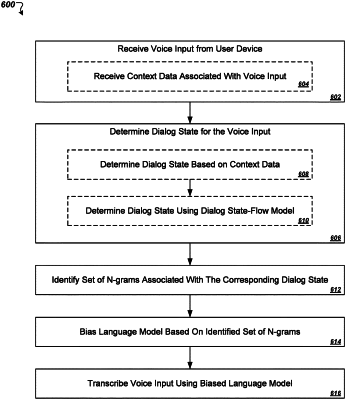
based on the context data, determining, from among multiple possible dialogs, a particular dialog corresponding to the particular stage from the multi-stage voice activity;
based on the particular dialog corresponding to the particular stage from the multi-stage voice activity, filtering the audio data to only include audio data associated with the particular dialog;
identifying, from a set of n-grams, a representative subset of n-grams associated with the particular dialog corresponding to the particular stage from the multi-stage voice activity based on one or more prior stages from the multi-stage voice activity corresponding to one or more prior transcription requests, each n-gram of the set of n-grams comprising a respective non-zero probability score;
biasing a language model by increasing the respective non-zero probability score for each n-gram of the identified representative subset of n-grams associated with the particular dialog; and
processing, using the biased language model, the filtered audio data to generate a transcription of the voice input.
|