| CPC G10L 15/197 (2013.01) [G10L 15/005 (2013.01); G10L 15/16 (2013.01); G10L 15/22 (2013.01)] | 14 Claims |
|
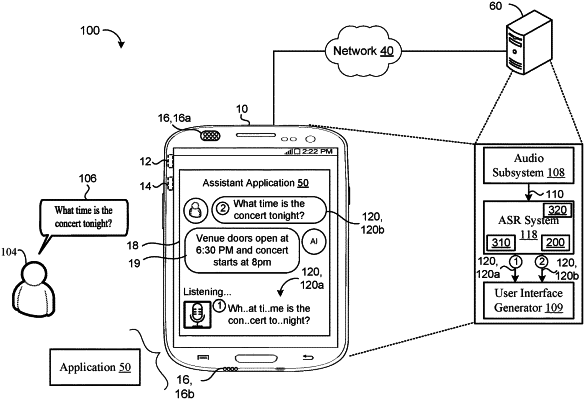
1. A computer-implemented method when executed on data processing hardware causes the data processing hardware to perform operations comprising:
receiving a sequence of acoustic frames extracted from audio data corresponding to an utterance;
receiving a language identifier indicating a language of the utterance;
during a first pass, processing, using a multilingual speech recognition model, the sequence of acoustic frames to generate N candidate hypotheses for the utterance;
during a second pass, for each candidate hypothesis of the N candidate hypotheses:
generating, using a neural oracle search (NOS) model, a respective un-normalized likelihood score based on the sequence of acoustic frames and the corresponding candidate hypothesis;
selecting a language-specific external language model from among a plurality of language-specific external language models each trained on a different respective language;
generating, using the language-specific external language model, a respective external language model score;
generating a standalone score that models prior statistics of the corresponding candidate hypothesis generated during the first pass; and
generating a respective overall score for the candidate hypothesis based on the un-normalized likelihood score, the external language model score, and the standalone score; and
selecting the candidate hypothesis having the highest respective overall score from among the N candidate hypotheses as a final transcription of the utterance.
|