| CPC G10L 15/02 (2013.01) [G10L 15/14 (2013.01); G10L 15/19 (2013.01); G10L 2015/025 (2013.01)] | 6 Claims |
|
1. A computer-implemented method for automatically enhancing natural language recognition in an Automated Speech Recognition (ASR) system, the method comprising:
receiving digitized speech audio comprising one or more of a directly digitized audio waveform, a spectrogram and a spectrogram processed into mel filter bank bin values;
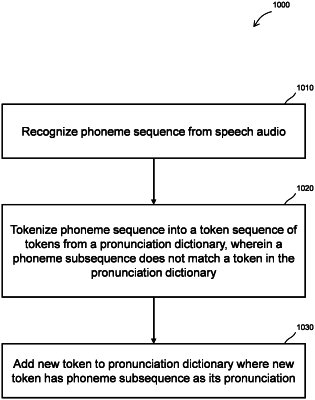
producing, via an acoustic model, a phoneme sequence based on the digitized speech audio;
generating a token sequence from the phoneme sequence via a pronunciation dictionary, wherein a token represents a word in the pronunciation dictionary;
identifying a phoneme subsequence from the phoneme sequence that does not match a token in the pronunciation dictionary;
identifying, via applying a semantic grammar to the token sequence, a slot for an entity where the phoneme subsequence fits in the semantic grammar, wherein the phoneme subsequence represents a new entity in the semantic grammar;
adding a new token to the pronunciation dictionary, the new token having the phoneme subsequence as its pronunciation; and
adding, to an entity list that is domain specific, the new entity with the phoneme subsequence as its pronunciation.
|