| CPC G10L 15/00 (2013.01) [G10L 19/02 (2013.01); G10L 21/18 (2013.01); G10L 25/18 (2013.01)] | 18 Claims |
|
1. A system for concurrent multi-path processing of audio signals for automatic speech recognition, the system comprising:
one or more processors; and
a memory storing instructions that, when executed by the one or more processors, cause the system to perform operations comprising:
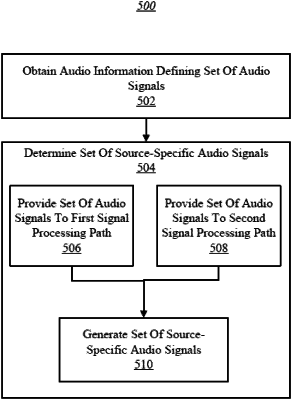
obtaining audio information defining a set of audio signals, individual audio signals in the set of audio signals conveying mixed audio content produced by multiple audio sources; and
determining a set of source-specific audio signals by demixing the mixed audio content produced by the multiple audio sources, individual source-specific audio signals representing individual audio content produced by specific individual audio sources of the multiple audio sources, wherein determining the set of source-specific audio signals comprises:
inputting time-frequency domain representations of the individual audio signals into one or more individual buffers to combine consecutive frames of the time-frequency domain representations into individual sets of consecutive frames of the time-frequency domain representations;
determining, based on the individual sets of consecutive frames of the time-frequency domain representations, a value of a demixing parameter for demixing the mixed audio content produced by the multiple audio sources, wherein the determining the demixing parameter comprises:
approximating individual reduced dimensionality representations of the individual sets of consecutive frames of the time-frequency domain representation of the individual audio signals;
decomposing the individual reduced dimensionality representations;
determining a current value of the demixing parameter based on the decomposed individual reduced dimensionality representations;
comparing the current value of the demixing parameter to a previous value of the demixing parameter; and
based on the comparison, setting the value of the demixing parameter as either the current value or a modified version of the current value;
concurrently providing the time-frequency domain representations of the individual audio signals to a second signal processing path to apply the value of the demixing parameter to the individual audio signals of the set of audio signals provided to the second signal processing path; and
generating the individual source-specific audio signals from the individual audio signals based on the application of the value of the demixing parameter to the individual audio signals.
|