| CPC G10L 13/10 (2013.01) [G10L 25/30 (2013.01); G10L 2013/105 (2013.01)] | 28 Claims |
|
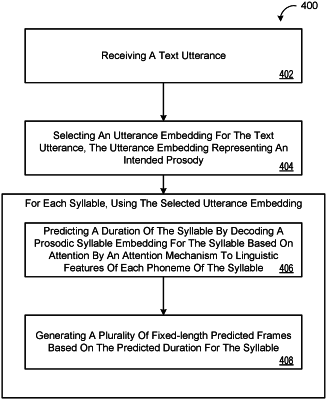
1. A method comprising:
receiving, at data processing hardware, a text utterance having at least one word, each word having at least one syllable, each syllable having at least one phoneme;
selecting, by the data processing hardware, an utterance embedding for the text utterance, the utterance embedding representing an intended prosody; and
for each syllable, using the selected utterance embedding:
predicting, by the data processing hardware, a duration of the syllable by decoding a prosodic syllable embedding for the syllable based on attention by an attention mechanism to linguistic features of each phoneme of the syllable; and
generating, by the data processing hardware, a plurality of fixed-length predicted frames based on the predicted duration for the syllable.
|