| CPC G06V 20/63 (2022.01) [G06F 18/214 (2023.01); G06N 3/04 (2013.01); G06N 3/084 (2013.01); G06V 10/225 (2022.01); G06V 10/40 (2022.01); G06V 30/10 (2022.01)] | 18 Claims |
|
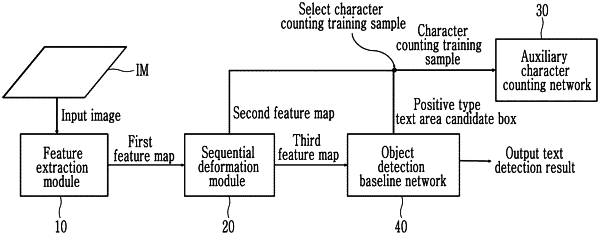
1. A method for detecting a scene text based on a feature extraction module, a sequential deformation module, an auxiliary character counting network, and an object detection baseline network, the method comprising:
extracting, by the feature extraction module, a first feature map for a scene image input based on a convolutional neural network, and delivering the first feature map to a sequential deformation module;
obtaining, by the sequential deformation module, sampled feature maps corresponding to sampling positions by performing iterative sampling through predicting an offset for each pixel of the first feature map, obtaining a second feature map by performing a concatenation operation in deep learning according to a channel dimension for the first feature map and the sampled feature maps obtained by the iterative sampling, and delivering the second feature map to an auxiliary character counting network;
obtaining, by the sequential deformation module, a third feature map by performing a feature aggregation operation for the second feature map in the channel dimension, and delivering the third feature map to the object detection baseline network; and
performing, by the object detection baseline network, text area candidate box extraction for the third feature map and obtaining a text area prediction result as a scene text detection result through regression fitting.
|