| CPC G06V 10/454 (2022.01) [G01S 17/89 (2013.01); G06T 3/02 (2024.01); G06T 7/74 (2017.01); G06T 11/00 (2013.01); G06V 10/806 (2022.01); G06V 10/82 (2022.01); G06V 20/58 (2022.01); G06T 2207/10028 (2013.01); G06T 2207/20068 (2013.01); G06T 2207/20084 (2013.01); G06T 2207/30261 (2013.01)] | 10 Claims |
|
1. An obstacle recognition method, wherein the method comprises:
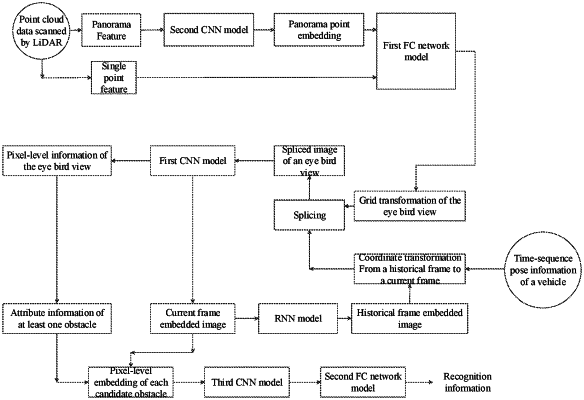
acquiring point cloud data scanned by a Light Detection and Ranging (LiDAR) and time-sequence pose information of a vehicle;
determining a spliced image of bird's eye view according to the point cloud data, the time-sequence pose information, and a historical frame embedded image, comprising:
determining a grid embedded image of the bird's eye view according to the point cloud data;
determining a conversion image of the historical frame embedded image according to the time-sequence nose information and the historical frame embedded image, comprising:
calculating an affine transformation parameter from a historical frame to a current frame according to the time-sequence pose information; and
transforming the historical frame embedded image by translation and rotation according to the affine transformation parameter to obtain the conversion image of the historical frame embedded image:
splicing the grid embedded image of the bird's eye view and the conversion image of the historical frame embedded image to obtain the spliced image of the bird's eye view;
inputting the spliced image into a preset first CNN model to obtain a current frame embedded image and pixel-level information of the bird's eye view; and
determining recognition information of at least one obstacle according to the current frame embedded image and the pixel-level information, comprising:
determining attribute information of the at least one obstacle according to the pixel-level information, the attribute information comprising position information and size information of the obstacle;
determining pixel-level embedding of each obstacle from the current frame embedded image according to the attribute information of each obstacle; and
inputting the pixel-level embedding of each obstacle into a preset neural network model to obtain recognition information of each obstacle, wherein the neural network model comprises a third CNN model and a second FC network model; and
the inputting the pixel-level embedding of each obstacle into a preset neural network model to obtain recognition information of each obstacle comprises:
inputting the pixel-level embedding of each obstacle into the third CNN model to obtain object-level embedding of each obstacle; and
inputting the object-level embedding into the second FC network model to obtain the recognition information of the at least one obstacle.
|