| CPC G06T 5/50 (2013.01) [G06T 3/40 (2013.01); G06V 10/44 (2022.01); G06V 10/761 (2022.01); G06T 2207/20221 (2013.01); G06T 2207/30196 (2013.01)] | 20 Claims |
|
1. An image processing method comprising:
acquiring, by a computing device, a first image comprising an image of a target person and a second image comprising an image of target clothes;
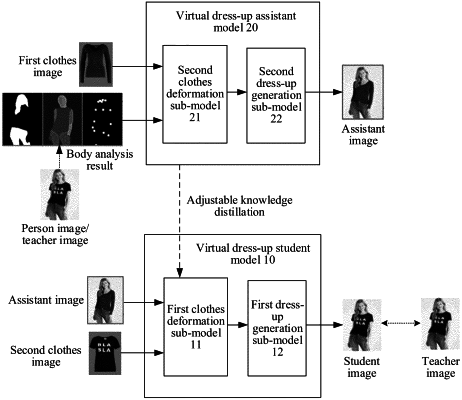
inputting, to a virtual dress-up assistant model, a body analysis result corresponding to a teacher image comprising a specified person and an image of to-be-worn clothes, to obtain an assistant image, wherein, in the assistant image, the specified person wears the to-be-worn clothes matching a body of the specified person;
inputting original clothes and the assistant image to a virtual dress-up student model, to obtain a student image, wherein, in the student image, the specified person wears the original clothes matching the body of the specified person in the assistant image, and the original clothes are clothes worn by the specified person in the teacher image;
updating parameters of the virtual dress-up student model based on image loss information between the student image and the teacher image;
generating, based on the virtual dress-up student model, image features of the first image, and image features of the second image, a target appearance flow feature for representing deformation of the target clothes matching a body of the target person, and generating, based on the target appearance flow feature, a deformed image of the target clothes matching the body; and
generating a virtual dress-up image, in which the target person wears the target clothes matching the body, by fusing the deformed image with the first image.
|