| CPC G06N 3/04 (2013.01) [G06N 20/00 (2019.01); G10L 15/16 (2013.01)] | 18 Claims |
|
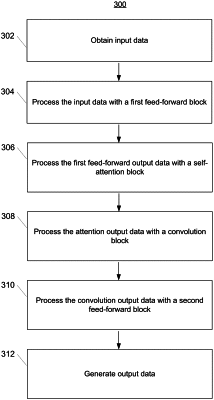
1. A computer-implemented method for efficiently processing data which accounts for both local and global dependencies, the method comprising:
accessing data descriptive of a machine-learned conformer model that comprises one or more conformer blocks, each of the one or more conformer blocks configured to process a block input to generate a block output, each of the one or more conformer blocks comprising:
a first feed-forward block configured to process the block input to generate a first feed-forward output;
a self-attention block configured to perform self-attention to process the first feed-forward output to generate an attention output;
a convolutional block configured to perform convolutions with a convolutional filter to process the attention output of the self-attention block to generate a convolutional output; and
a second feed-forward block configured to process the convolutional output of the convolutional block to generate a second feed-forward output;
obtaining input data, wherein the input data comprises audio data; and
processing the input data with the machine-learned conformer model to generate output data, wherein the output data comprises text data, wherein the machine-learned conformer model comprises the convolutional block that processes outputs of the self-attention block without performing parallel processing with the self-attention block and the convolutional block, and wherein the convolutional block and the self-attention block are between the first feed-forward block and the second feed-forward block.
|