| CPC G06F 9/30156 (2013.01) [G06F 9/30036 (2013.01); G06F 16/907 (2019.01); G06F 18/2155 (2023.01); G06F 40/00 (2020.01); G06F 40/126 (2020.01); G10L 25/30 (2013.01)] | 19 Claims |
|
1. A method comprising:
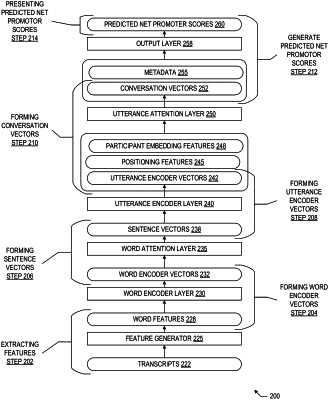
extracting, from a transcript of a conversation, a plurality of word features, a plurality of positioning features, a plurality of participant embedding features, and a plurality of metadata;
forming a word encoder vector by multiplying weights of a word encoder layer of a trained hierarchical attention model to one or more word features of the plurality of word features, wherein the trained hierarchical attention model is trained to generate a predicted net promoter score from the transcript by:
forming a plurality of training scores from a plurality of training transcripts using a hierarchical attention model comprising a word level model and an utterance level model, wherein the word level model comprises the word encoder layer and a word attention layer, and wherein the utterance level model comprises an utterance encoder layer and an utterance attention layer,
comparing the plurality of training scores to a plurality of transcript labels to form a plurality of updates, and
updating the hierarchical attention model with the plurality of updates to generate the trained hierarchical attention model;
forming a sentence vector by multiplying weights of the word attention layer of the trained hierarchical attention model to a plurality of word encoder vectors comprising the word encoder vector;
forming an utterance encoder vector by multiplying weights of the utterance encoder layer of the trained hierarchical attention model to the sentence vector;
forming a conversation vector by multiplying weights of the utterance attention layer of the trained hierarchical attention model to a plurality of utterance encoder vectors comprising the utterance encoder vector, wherein the utterance encoder vector is formed from the sentence vector and is combined with one or more positioning features of the plurality of positioning features identifying positions of utterances in the transcript and with one or more participant embedding features of the plurality of participant embedding features;
generating the predicted net promoter score by multiplying weights of an output layer of the trained hierarchical attention model to the conversation vector combined with the plurality of metadata; and
presenting the predicted net promoter score in a list of conversations comprising the conversation.
|