| CPC G06F 40/58 (2020.01) | 18 Claims |
|
1. A system comprising:
at least one memory storing instructions; and
at least one processor configured to execute the instructions to perform operations for multi-language, multi-task speech recognition, the operations comprising:
obtaining a transformer model including an encoder and a decoder, the transformer model trained to transcribe or translate audio data in multiple languages using labeled audio data, the labeled audio data including first audio segments associated with first same-language transcripts of the first audio segments and second audio segments associated with second different-language transcripts of the second audio segments; and
generating an output transcript from an input audio segment using the transformer model, generation including:
configuring a decoder input with a language token corresponding to a first language;
configuring the decoder input with a task token; and
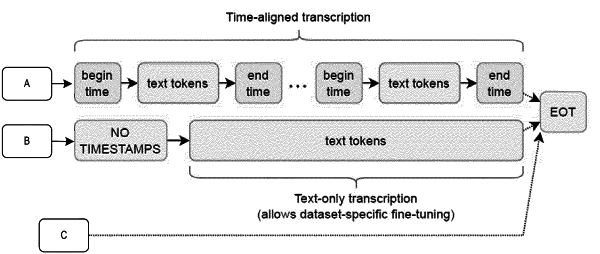
autoregressively configuring the decoder input with a first timestamp token predicted by the decoder based on an absence of a notimestamp token in the decoder input.
|