| CPC G06F 21/6227 (2013.01) [G06F 18/214 (2023.01); G06F 18/22 (2023.01); G06N 20/00 (2019.01); G06F 2221/2141 (2013.01)] | 20 Claims |
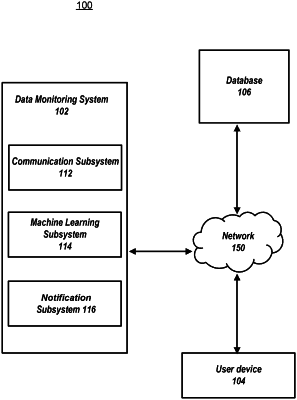
|
1. A system for using machine learning and lineage data to prevent derivative data access by users inadvertently authorized to access the derivative data, the system comprising:
storage circuitry configured to store lineage data corresponding to a plurality of datasets, wherein the plurality of datasets comprises an original dataset and a derivative dataset derived from the original dataset, wherein the lineage data indicates a process used to create the derivative dataset from the original dataset; and
control circuitry configured to perform operations comprising:
identifying, based on a processing of the lineage data, the original dataset as a source of the derivative dataset;
in response to the original dataset being identified as the source, obtaining access data indicating respective access rights related to the original dataset and the derivative dataset;
determining, based on the access data, that a user has access to the derivative dataset and is restricted from accessing the original dataset;
in response to determining that the user has access to the derivate dataset and is restricted from accessing the original dataset, obtaining, via a machine learning model, a similarity score indicating a level of similarity between the original dataset and the derivative dataset, the machine learning model generating vector representations of the original dataset and derivative dataset, respectively, to obtain the similarity score; and
in response to determining that the similarity score exceeds a threshold score, modifying access rights of the user to the derivative dataset such that (i) the modification disables data access of the user to a first portion of the derivative dataset that was accessible to the user prior to the modification and (ii) the modification maintains data access of the user to a second portion of the derivative dataset different from the first portion of the derivative dataset.
|