| CPC G06F 21/604 (2013.01) [G06F 16/258 (2019.01)] | 18 Claims |
|
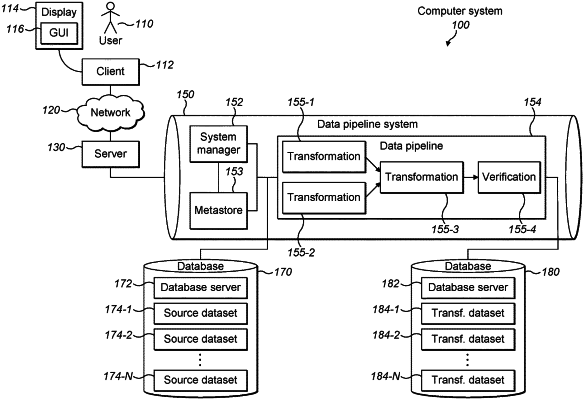
1. A computer-implemented method for enforcing data security constraints in a data pipeline, wherein the data pipeline takes one or more source datasets as input and performs one or more data transformations on them, the method comprising:
within a first stage of the data pipeline, generate a first transformed dataset by performing a first data transformation on a first subset of entries of the one or more source datasets, wherein the first subset is defined according to one or more first data security constraints, wherein the one or more first data security constraints are associated with one or more columns or rows, and wherein an entry is accepted into or rejected from the first transformed dataset based on a comparison between the entry and the one or more first data security constraints;
within a second stage of the data pipeline, generate a second transformed dataset by performing a second data transformation on a second subset of entries of the one or more source datasets;
validate the second transformed dataset according to a pattern or constraint specified by the first transformed dataset, wherein the validating comprises comparing entries of the second transformed dataset against the first transformed dataset and filtering out any fields of the second transformed dataset that fail to conform to the pattern or constraint specified by the first transformed dataset, the first transformed dataset specifying a previously unknown or undefined criteria; and
providing an alert if any fields of the second transformed dataset fail to conform to the pattern.
|