| CPC G06F 16/24578 (2019.01) [G06F 16/2282 (2019.01)] | 20 Claims |
|
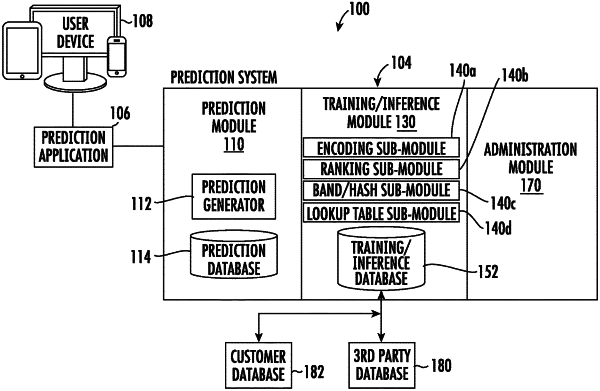
1. A computer system, comprising:
one or more memory units comprising one or more instructions;
one or more hardware processors communicatively coupled to the one or more memory units, the one or more hardware processors configured, upon executing the one or more instructions, to:
for each of a plurality of lookup tables:
determine a plurality of hyperparameters, the plurality of hyperparameters comprising a minimum band size hyperparameter, a band growth function hyperparameter, and a minimum match volume hyperparameter;
access a first table that comprises a first set of data, wherein the first set of data comprises a plurality of first independent variables;
one-hot encode one or more of the first independent variables of the plurality of first independent variables of the first set of data, wherein a second table is created that comprises the first set of data with all of the plurality of first independent variables of the first set of data being one-hot encoded;
rank the plurality of first independent variables of the second table, and sort the plurality of first independent variables of the second table into a first order based on the rank, wherein each of the plurality of first independent variables of the second table is ranked based on a linear correlation between the respective first independent variable and a target metric;
distribute the sorted first independent variables of the second table into a plurality of first bands of first varying resolution based on (1) the first order of the sorted first independent variables of the second table, (2) the minimum band size hyperparameter, and (3) the band growth function hyperparameter, wherein the plurality of first bands comprise a top band that comprises a smallest portion of the sorted first independent variables of the second table in comparison to each of the other first bands of the plurality of first bands, wherein the smallest portion of the sorted first independent variables of the second table is defined by the minimum band size hyperparameter, wherein each of the other first bands of the plurality of first bands includes a larger portion of the sorted first independent variables of the second table in comparison to a previous first band of the plurality of first bands, wherein each of the larger portions of the sorted first independent variables of the second table is defined by the band growth function hyperparameter;
generate a first hash for each record of the first set of data of the second table at each level of the plurality of first bands;
generate a respective lookup table of the plurality of lookup tables based on the first hashes, wherein the respective lookup table comprises a grouping of one or more of the records of the first set of data of the second table at each of the first hashes, wherein the respective lookup table further comprises one or more aggregations for each of the first hashes, wherein the respective lookup table further comprises one or more predicted values for each of the first hashes, wherein the one or more predicted values for each of the first hashes comprises at least one of the one or more aggregations for each of the first hashes;
access a third table that comprises a second set of data, wherein the second set of data comprises a plurality of second independent variables;
one-hot encode one or more of the second independent variables of the plurality of second independent variables of the second set of data based on a mapping of the one-hot encoding of all of the plurality of first independent variables of the first set of data, wherein a fourth table is created that comprises the second set of data with all of the plurality of second independent variables of the second set of data being one-hot encoded;
rank and sort the plurality of second independent variables of the fourth table into a second order that is the same as the first order of the sorted first independent variables of the second table;
distribute the sorted second independent variables of the fourth table into a plurality of second bands of a second varying resolution, wherein the distribution of the sorted second independent variables of the fourth table into the plurality of second bands of the second varying resolution is the same as the distribution of the sorted first independent variables of the second table into the plurality of first bands of the first varying resolution, the plurality of second bands of the second varying resolution is the same as the plurality of first bands of the first varying resolution;
generate a second hash for each record of the second set of data of the fourth table at each level of the plurality of second bands, so as to create a model-ready table;
join the respective lookup table to the model-ready table on matching hashes of the first and second hashes; and
remove one or more first bands of the plurality of first bands and/or one or more second bands of the plurality of second bands based on the minimum match volume hyperparameter;
receive a user prediction request from a user device;
generate a prediction report based on one or more lookup tables of the plurality of lookup tables; and
transmit the prediction report to the user device.
|