| CPC G06F 15/7839 (2013.01) [G06F 7/5443 (2013.01); G06F 7/575 (2013.01); G06F 7/588 (2013.01); G06F 9/3001 (2013.01); G06F 9/30014 (2013.01); G06F 9/30036 (2013.01); G06F 9/3004 (2013.01); G06F 9/30043 (2013.01); G06F 9/30047 (2013.01); G06F 9/30065 (2013.01); G06F 9/30079 (2013.01); G06F 9/3887 (2013.01); G06F 9/5011 (2013.01); G06F 9/5077 (2013.01); G06F 12/0215 (2013.01); G06F 12/0238 (2013.01); G06F 12/0246 (2013.01); G06F 12/0607 (2013.01); G06F 12/0802 (2013.01); G06F 12/0804 (2013.01); G06F 12/0811 (2013.01); G06F 12/0862 (2013.01); G06F 12/0866 (2013.01); G06F 12/0871 (2013.01); G06F 12/0875 (2013.01); G06F 12/0882 (2013.01); G06F 12/0888 (2013.01); G06F 12/0891 (2013.01); G06F 12/0893 (2013.01); G06F 12/0895 (2013.01); G06F 12/0897 (2013.01); G06F 12/1009 (2013.01); G06F 12/128 (2013.01); G06F 15/8046 (2013.01); G06F 17/16 (2013.01); G06F 17/18 (2013.01); G06T 1/20 (2013.01); G06T 1/60 (2013.01); H03M 7/46 (2013.01); G06F 9/3802 (2013.01); G06F 9/3818 (2013.01); G06F 9/3867 (2013.01); G06F 2212/1008 (2013.01); G06F 2212/1021 (2013.01); G06F 2212/1044 (2013.01); G06F 2212/302 (2013.01); G06F 2212/401 (2013.01); G06F 2212/455 (2013.01); G06F 2212/60 (2013.01); G06N 3/08 (2013.01); G06T 15/06 (2013.01)] | 20 Claims |
|
1. A general-purpose graphics processor comprising:
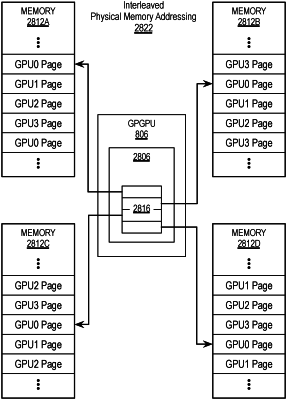
a memory access pipeline configured to access a memory system having physically interleaved memory addressing, the memory system including:
a first memory device that is local to the general-purpose graphics processor; and
a second memory device that is remote to the general-purpose graphics processor and local to a first remote general-purpose graphics processor,
wherein the memory access pipeline includes hardware to facilitate access to physically interleaved memory pages of the memory system, the physically interleaved memory pages include a first physical memory page and a second physical memory page, the first physical memory page to be stored on the first memory device and the second physical memory page to be stored on the second memory device, and
wherein the first physical memory page is to be contiguous with the second physical memory page and the hardware of the memory access pipeline is to satisfy memory access requests for contiguous physical memory pages from the first memory device and the second memory device to cause memory access latency for the memory access requests to be an average of the memory access latency of the first memory device and the second memory device.
|