| CPC H04N 7/157 (2013.01) [G06F 3/0484 (2013.01); G06T 11/00 (2013.01); G06T 13/80 (2013.01); H04L 12/1822 (2013.01); H04L 65/1069 (2013.01); H04L 65/403 (2013.01); H04N 7/152 (2013.01)] | 20 Claims |
|
1. A system for triggering livestream communications between users based on proximity-based criteria for avatars within virtual environments that correspond to the users, the system comprising:
a first computer terminal comprising a first user interface and a first webcam;
a second computer terminal comprising a second user interface and a second webcam;
a third computer terminal comprising a third user interface and a third webcam;
a server configured to:
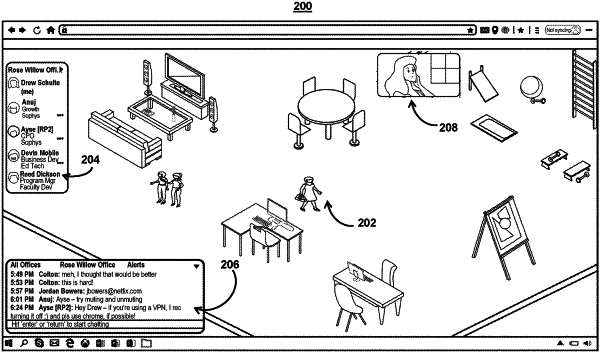
generate for simultaneous display a first virtual environment on respective user interfaces, wherein the respective user interfaces are accessible to each of a first user, a second user, and a third user, wherein the first user, the second user, and the third user are located remotely from each other;
generate for display, in the first virtual environment, a first avatar corresponding to the first user, a second avatar corresponding to the second user, and a third avatar corresponding to the third user, wherein the first avatar comprises a virtual representation of the first user that may be navigated about the first virtual environment, wherein the second avatar comprises a virtual representation of the second user that may be navigated about the first virtual environment, and wherein the third avatar comprises a virtual representation of the third user that may be navigated about the first virtual environment;
generate for display on the respective user interfaces for the first user and the second user a conversation, wherein the conversation comprises a livestream communication using the first webcam and the second webcam;
determine, for the first avatar, a first position in the first virtual environment;
determine, for the third avatar, a third position in the first virtual environment; and
add, without user input, the third user to the conversation based on the first position and the third position, wherein adding the third user to the conversation comprises generating for display, the livestream communication, on the respective user interfaces using the first webcam, the second webcam, and the third webcam, and wherein adding the third user to the conversation based on the first position and the third position further comprises:
determining, for the second avatar, a second position in the first virtual environment;
retrieving a first threshold distance for adding the third user to the conversation, wherein the first threshold distance indicates a maximum distance from any avatars in the conversation for adding a new avatar to the conversation;
determining a first distance, wherein the first distance is between the third position and the second position; and
comparing the first distance to the first threshold distance to determine to add the third user to the conversation.
|