| CPC H04L 67/148 (2013.01) [G06F 9/4806 (2013.01); G06F 9/505 (2013.01); G06F 15/17331 (2013.01); H04L 67/133 (2022.05)] | 11 Claims |
|
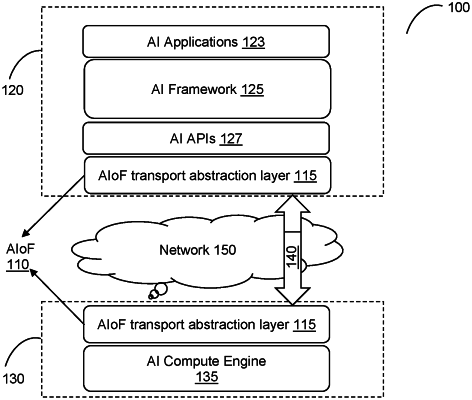
1. A method for communicating artificial intelligence (AI) tasks for a server chaining, comprising:
establishing a first connection between an AI client and a first AI server;
encapsulating a request to process an AI task in at least one request data frame compliant with a communication protocol;
transporting the at least one request data frame over a network using a transport protocol over the first connection to the first AI server, wherein the first AI server spans the AI task over at least one second AI server, wherein the transport protocol provisions transport characteristics of the AI task and the transport protocol is different than the communication protocol, wherein AI task includes processing of a single compute graph thereby allow spanning the processing of the compute graph over one more AI servers;
establishing a second connection between the first AI server and the at least one second AI server;
transporting the at least one request data frame over using the transport protocol over the second connection;
defining a plurality of queues to support messages exchanged between the AI client and first AI server; and
defining a plurality of queues to support messages exchanged between the first AI server and each of the second AI server, wherein each of the plurality of queues are allowed to differentiate different users, flows, AI tasks, and service priorities.
|